Some of the biggest discussions happening in IT right now is around data. Data is generating in a ceaseless flow as infrastructures evolve and scale. As growing masses of data start to fill up the available spaces in storage systems, it brings to fore the matter of searchability of datasets. In the big data world, there are only two ways to go – leverage data by extracting value out of it – for which strong searchability is paramount – or sink under the weight of it.
At the recent Security Field Day event, Cribl addressed this issue that is echoing in IT with organizations amassing data in unforeseen amounts. At the event, Cribl introduced the new Cribl Search – a function that makes it possible to mine petabytes of observability data at the edge.
Data Has Strings Attached
Given the current state of things, we all can agree on one thing – we have far too much data than we can comfortably handle. New challenges start to emerge as the data balloon continues to grow bigger. The first of them is cost. Organizations are constantly wrestling with the appalling costs of storing data in the cloud.
Even though only a small fraction of the data produced is actually preserved, the problem of having to move data closer every time teams want to query datasets shoots the cost through the roof. Nick Heudecker, Sr Director of Marketing Strategy at Cribl notes, “Even if that data is not valuable, you are paying for every byte you are bringing in from each of your data sources.”
Appended to the problem of excess data is the searchability factor. Without a strong and optimized query function, annotating vast datasets is like going looking for Waldo.
Querying Data at Endpoints
Cribl takes aim at “the old problem of having to move everything that you want to search before you can actually do anything with it” with Cribl Search. The chief driver for Cribl Search was to find an easier and less expensive way to access data without companies footing huge bills for relocating datasets they need to query. The alternate is not knowing where anything is, and lose value trapped in the data.
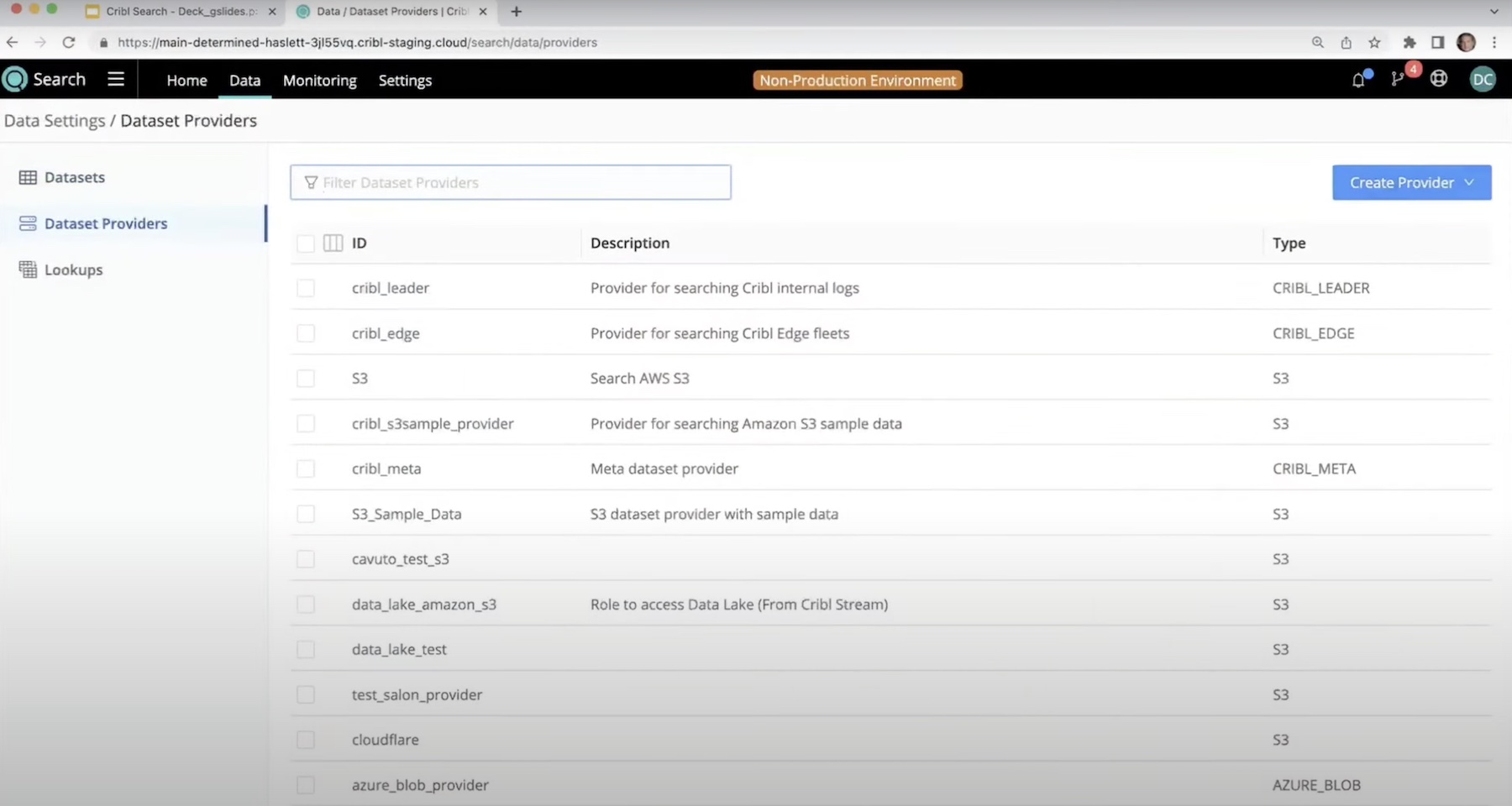
Cribl Search was launched in November and is currently available to all users on Cribl Cloud. Cribl Search lets organizations search data easily without having to change their locations. To do that, Cribl Search upends the standard agent model and uncovers a new possibility.
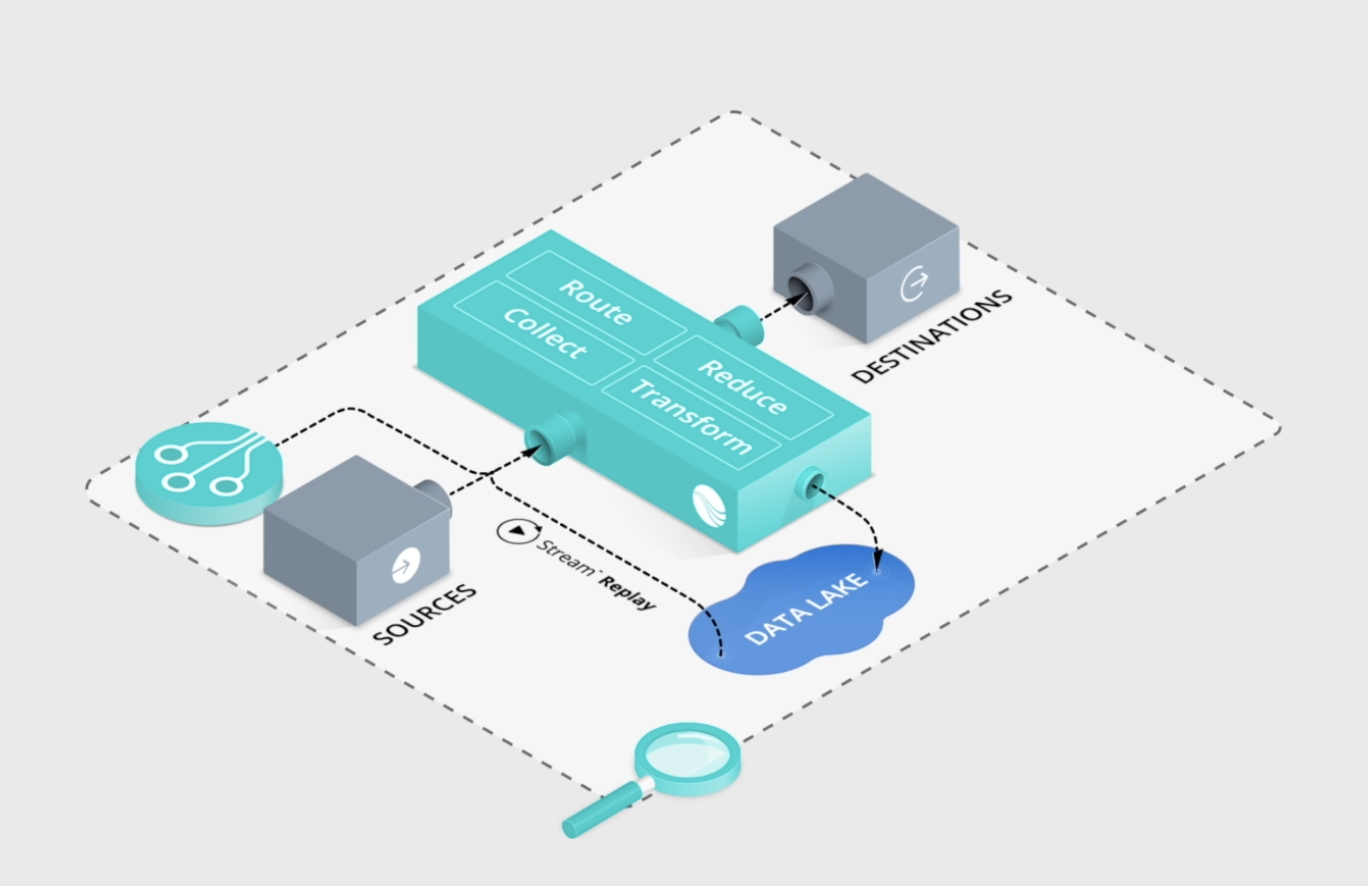
Instead of hauling data back to cloud, Cribl Search lets users search data at the edge before it is moved closer for analysis as opposed to the standard practice of moving before querying. This mitigates the cost problem which encumbers a lot of companies that do not have the wherewithal to move large volumes of data from edge to cloud.
The second set of customers that it is designed for are companies that have data everywhere and could use a global search capability that is compatible with data in different formats and lets them search natively inside their buckets.
The New Cribl Search on Cribl Cloud
At the Security Field Day event, Cribl showcased Cribl Search. In a short presentation, Heudecker gave a quick overview of what Cribl seeks to resolve with its new search product and how it does what it does. The presentation was followed by a longer demo that showed off Cribl Search in action.
Cribl Search allows data to be queried at rest, before they are repatriated for closer analysis. With its kind of integration, engineers can query whatever data they want in the observability pipeline, no matter the format. That data could be at the source host, in the data lake, or moving through the pipeline or at the destination. Users can customize it with alerting features to make the search results more pinpointed.
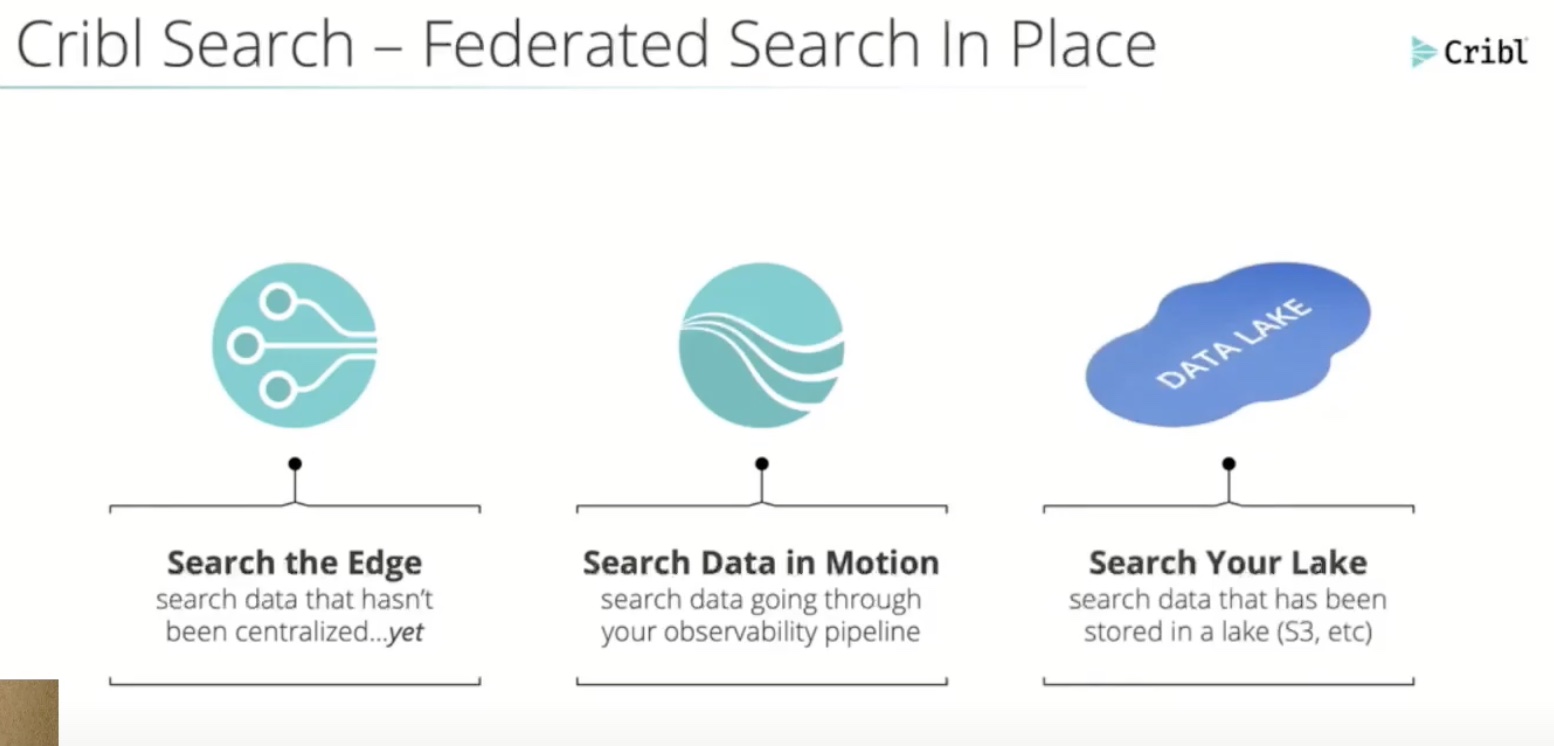
This robust compatibility has been possible because Cribl Search uses Kusto, an open-source query language from Microsoft. Heudecker explained, “You can use this language across each of the destinations whether it’s data at the edge, data flowing through the stream, or data at rest.” This makes it possible to query multiple formats of data.
Cribl Search comes with a central GUI that is loaded with information and capabilities. Cribl customers may already be partly familiar with the interface, but the new UI offers changes beyond cosmetic. The interface is boosted with more options to customize and history capabilities among other things. One of the things Heudecker highlighted during the presentation is its ability to lets users query data in motion as it moves through the Cribl stream.
Cribl Search is system-agnostic and easy to deploy as it is to use. It can federate query to any location, and Cribl will be adding more federated search capabilities to it going forward.
Wrapping Up
With fresh loads of valuable data delivered every day, organizations are competing against the clock to gain value out of it all. Cribl Search benefits by cutting down people hours and costs. Being native to Cribl Cloud, it eliminates the need to use proprietary search tools or hire skilled people to operate those tools. Additionally, by letting administrators query data first, it enables users to move data to cloud more selectively making sure that only data that yields the most value lives in cloud while the not-so-important ones stay at the edge.
Check out the Cribl Search demonstration and other such presentations by Cribl from the recent Security Field Day event.