The pursuit of deploying usable artificial intelligence (AI) within organizations is somewhat like aspiring to change the world. Everybody wants to do it, everybody talks about it, and yet few have the practical experience to do it.
With AI, the biggest barrier to entry is building a technology stack that can help achieve worthwhile, credible results. The key difference between generative AI or any variants of AI is complex I/O patterns. Data that goes into training models is picked up near the edge – from factory floors, IoT devices in the field, and so on. Through a storage network, it is transmitted to a central hub as logs and other unstructured data like JSON documents and images.
To obtain valid training material out of this data, it has to be cleansed, tested and retested on repeat. All of these amount to significantly varying I/O demands – before any useful intelligence is produced.
DW and OLTP Were Simpler Days
Only a decade ago, storage admins were concerned with just two major I/O patterns for their users. Except for transaction logging (sequential writes), OLTP workloads tended towards intense random reads and random writes as systems captured transactions from customer transactions. Their counterpoint, data warehousing (DW), typically required full table scans or complex joins to filter data (sequential reads). Additionally, enormous volumes of data had to be loaded and/or transformed (sequential writes).
Online analytic processing (OLAP) workloads were just coming to the forefront. As the machine learning craze took off, it introduced mixed I/O workloads which most storage systems at the time could handle adequately well.
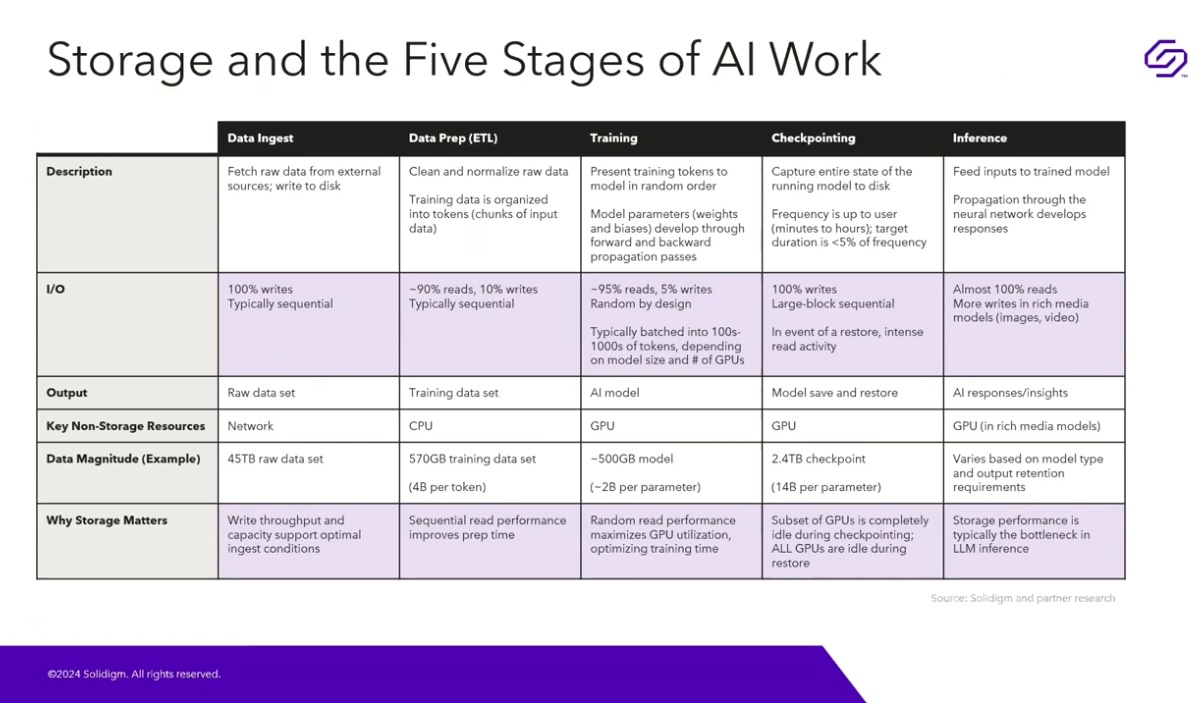
But typical AI workloads have expanded well beyond those simpler I/O classifications since. They now require extensive data cleansing to deliver accurate features to the models. Leveraging the cleansed datasets for training large language models (LLMs) and generative AI algorithms presents yet another I/O pattern. Checkpointing the results of the LLMs is imperative to ensure that the models are learning everything within valid ranges of accuracy.
After these iterative processes complete, is it reasonably safe to allow AI to provide actionable insights when applied against real-world data. Otherwise, there’s a good chance that hallucinations may appear when least expected.
Another wrinkle is GPU utilization. LLMs are hungry beasts that require powerful graphics processing units (GPUs) specifically designed to handle the complex math of training, checkpointing, and returning valid and actionable AI insights. An idle GPU is one of the highest infrastructure debt in the enterprise AI computing landscape. Because their electrical power demands is significantly higher than their predecessors, they need to be kept busy all the time.
The Room(s) Where I/O Happens
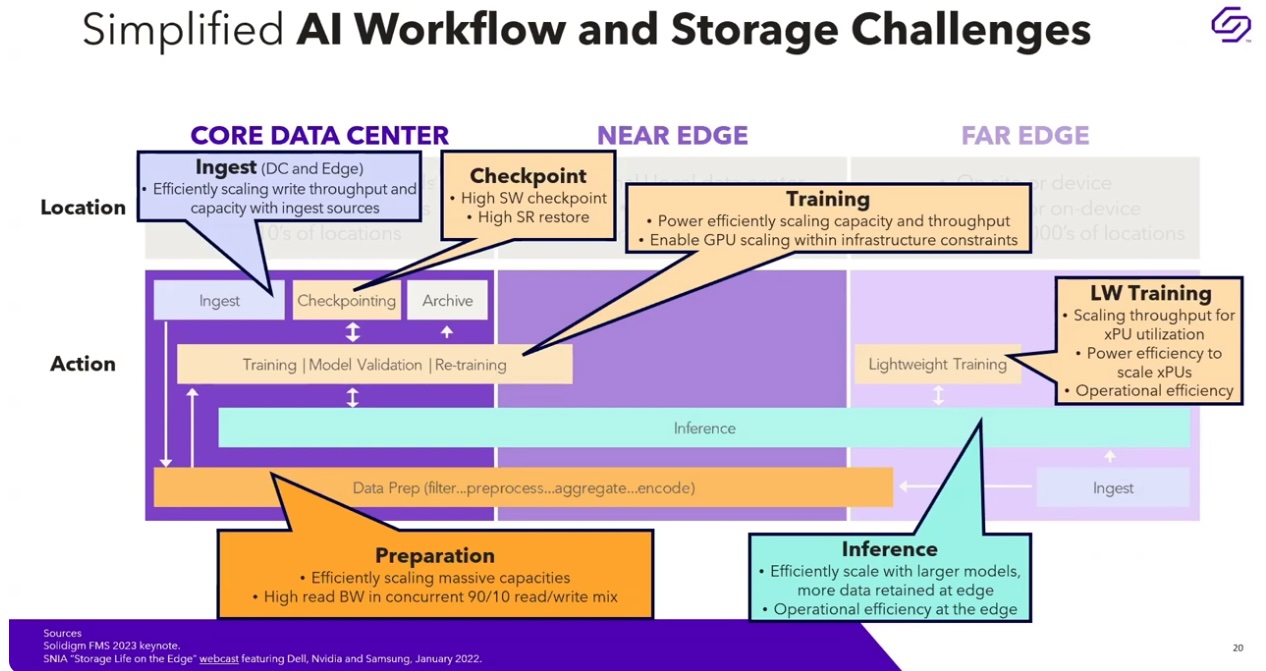
An obvious way to keep a GPU busy round the work is to run multiple workloads simultaneously. That strategy certainly maximizes the use of these expensive components. But on the flip side, it introduces a constantly-shifting I/O pattern of demand for enterprise computing platforms that are concurrently loading and transforming data (large sequential read/write) during ingest, overlaid with mostly random reads during training cycles, compounded by bulky sequential writes while checkpointing, possibly colliding with high read activity as valid models arrive at real-world insights.
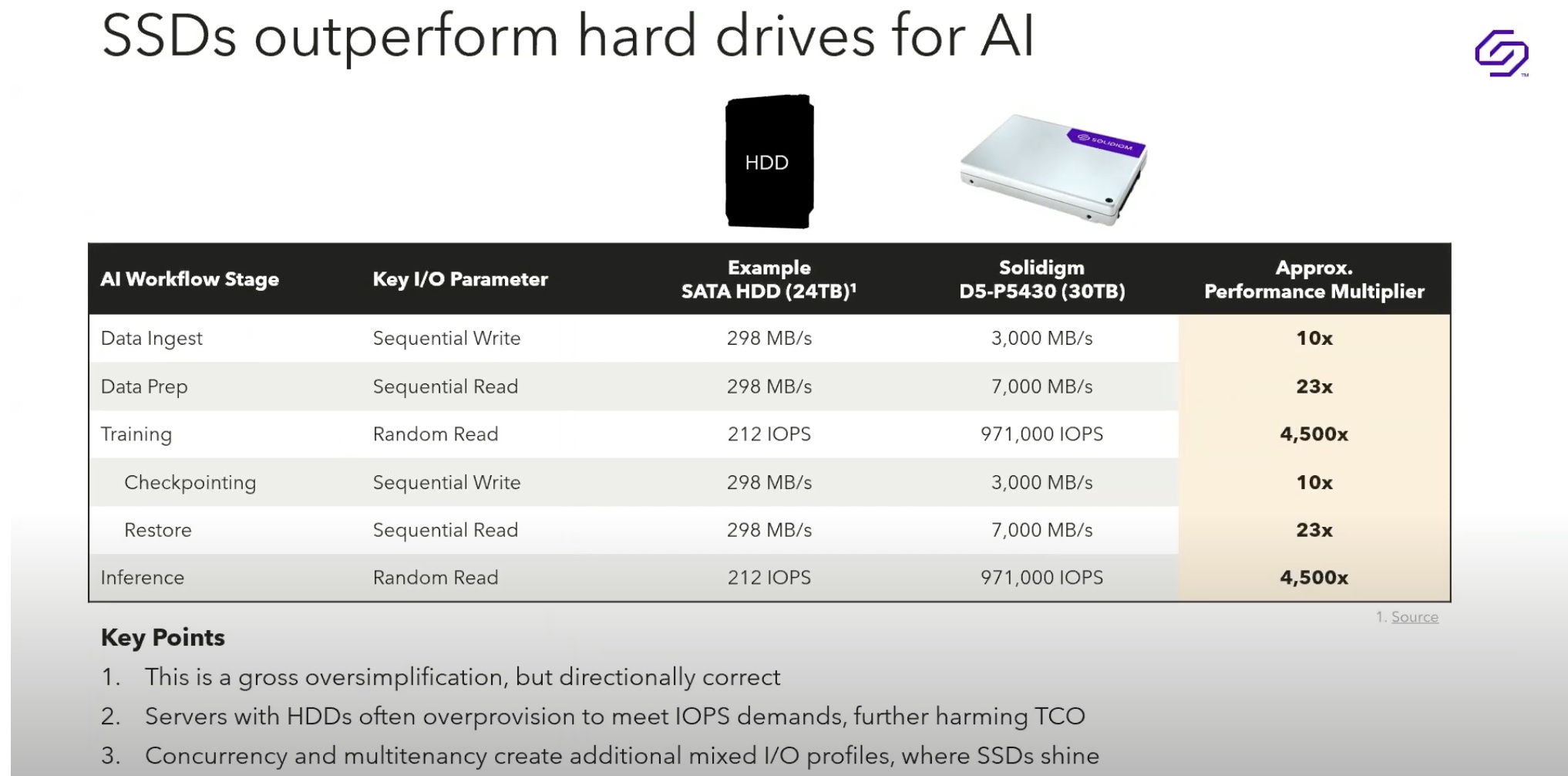
Building an enterprise storage system that can handle these myriad I/O demands – seems like an insurmountable task. HDDs may seemingly have a capacity advantage where AI’s petabyte range storage demands are concerned, but they cannot offer sufficient IOPS for extreme random read/writes without over-provisioning. That approach requires even more power and cooling, to say nothing of the extra floor space for racks of hot, thirsty HDDs. By contrast, QLCs have a far greater advantage there.
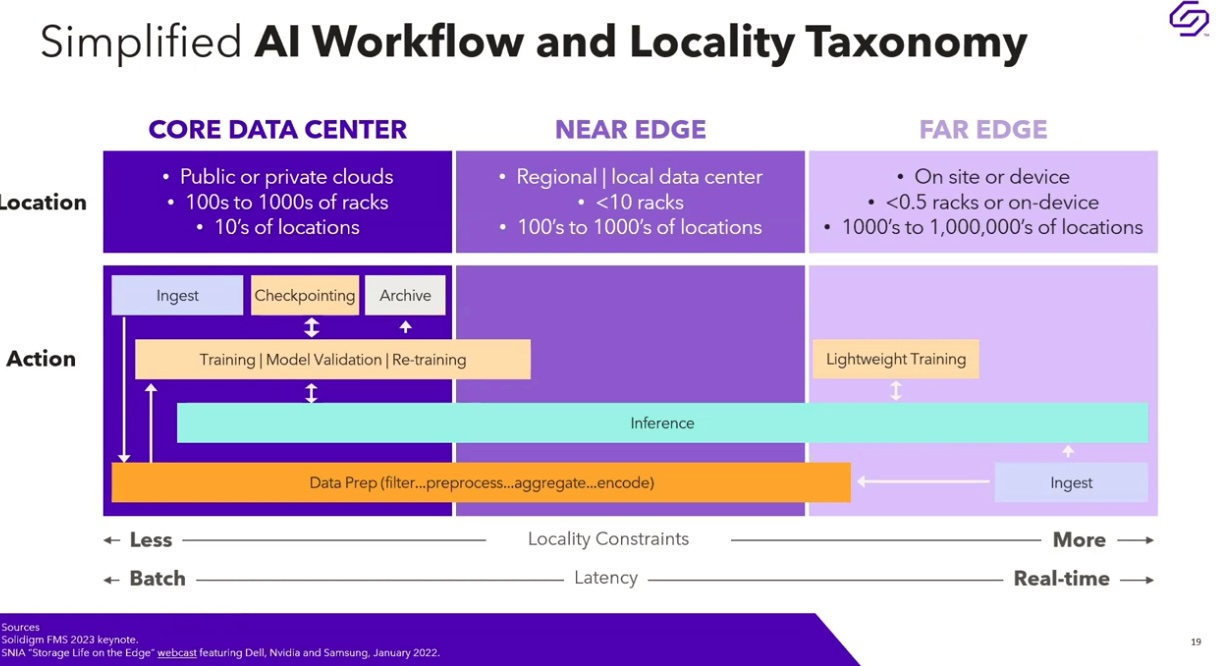
The sources of all these myriad datapoints lay potentially far outside the walls of the traditional datacenter. A manufacturer’s factory floor may have hundreds of IoT sensors detecting everything from overheated machine tools to diminishing raw materials in hoppers. Similarly, an electric utility may have thousands of IoT devices like smart meters, monitoring every single customer’s electric usage every quarter hour. That means the edge of the datacenter have to handle incredibly fast ingest demands for extremely small packets of information from that extended array of sensors.
A Storage System Designed for AI Demands
Solidigm has designed a revolutionary storage solution that tackles the intense demands of AI workloads. Their product line includes a wide selection of SSD models purpose-built to overcome the aforementioned issues.
As it turns out, SSDs are inherently advantageous for AI workload. Superior to HDDs for handling diverse throughput demands like prolonged sequential read/write, during data ingestion and transformation, they also provide long-term high-capacity storage volume. As a result, they make a better choice for the intense demands of random read/write activity while training, checkpointing, and delivering insight for LLMs, ensuring that those hungry GPUs keep consuming data.
Since real-world AI workloads often consume payloads from diverse arrays of sensors and IoT devices, SSDs respond more flexibly to demands for immediate capture of logs, images, and unstructured data. Best of all, they provide these capabilities with a much smaller power, cooling, and physical rack space footprint within datacenters.

Solidigm’s Cloud Storage Acceleration Layer (CSAL) software acts as the cherry on top. CSAL is an open-source software that provides write-shaping – in essence, sequentializing that I/O – via extremely fast write buffers within storage class memory (SCM) SSDs before the incoming data stream is eventually written to higher-capacity QLC SSDs. Since SSDs do eventually “wear out” from write activity over years of use, serializing the I/O patterns increases their lifespan without compromising on the workload performance demands.
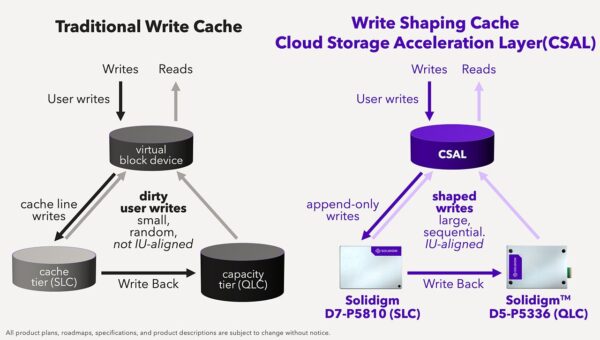
Conclusion
Solidigm’s SSD-based storage solutions – particularly CSAL – offers intriguing possibilities for storage engineers who are struggling to accommodate the exponential demands of AI workloads.
There’s a wealth of information on Solidigm’s solution at Tech Field Day’s recent AI Field Day event, and a deeper explanation of how CSAL works can be found here.