StorPool’s SDS 2.0 is a purpose-built, fast, and efficient block storage software. The solution features advanced block-level software-defined storage, fully distributed, scale-out, online changes of everything, and it runs on several standard servers (both converged or stand-alone). SDS 2.0 focuses on high-performance primary storage and replaces traditional SAN and all-flash arrays.
Its focus is on new-age IT stacks such as Kubernetes, but it still supports legacy VMware and other systems. SDS 2.0 is an SD storage plane running on powered servers built from the ground up to provide private and public clouds with the fastest and most reliable storage solution possible.
StorPool presented its latest version of SDS, 2.0 at Cloud Field Day 9.
Purpose-Built
Because SDS 2.0 is purpose-built, it is not a collection of random pieces stitched together and, according to StorPool, it replaces traditional storage arrays and all-flash arrays, as well as other store software and SD storage systems.
Its SD storage runs on Linux, and there are no special hardware requirements; it is a true SD storage plane. If a company is running a modern X86 server, SDS 2.0 will work. To get high performance, users need good network interface cards and NVME drives. StorPool can scale the solution to work on previous generation storage node helpers.
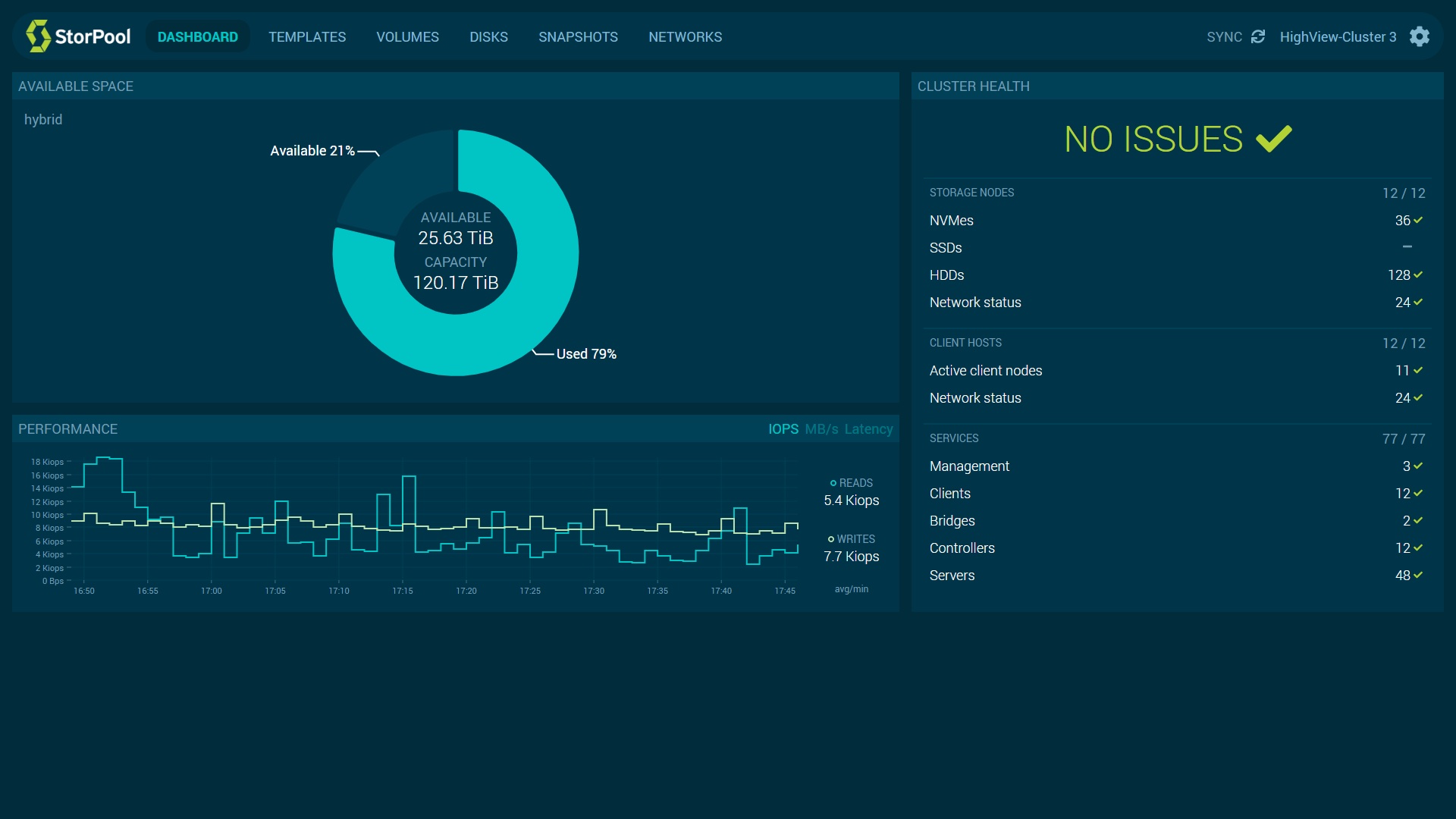
The system delivers 150,000+ IOPS, and 1,500+ MB/s per storage server on SATA SSD drives with just three CPU cores and 16 GB RAM; 0.15-0.3 ms latency. It supports SAS, NVMe & RDMA.
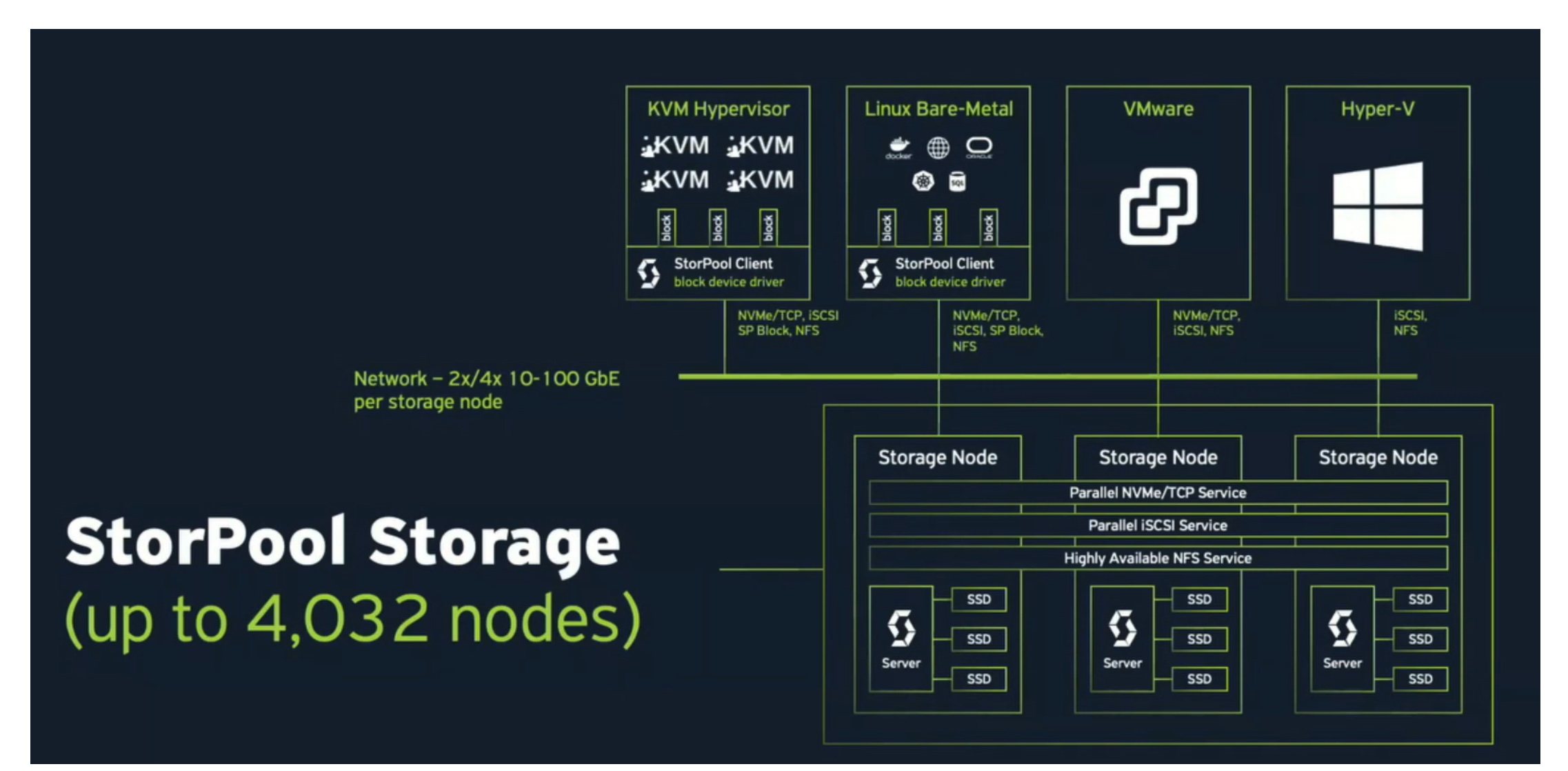
SDS 2.0 is a scale-out system; it starts with three nodes, three controllers, each with its own local drives. It does efficient pooling of capacity and performance. When companies use nodes through the system, they don’t just add capacity; it also increases system performance.
Volume Capacity
Users can create a volume larger than the capacity of a single storage node. There is nothing in the system that prevents you from doing that. It is a pooling of all the drives regardless of which server they are in. It has its own copy only storage format, which gives it thin provisioning and snapshots.
SDS 2.0 has end-to-end data integrity and a technology guarantee that the data you put in is the data you get back. It does this using three-way replication across storage nodes. So it is not within a storage node. If a storage node dies, you have two additional copies.
SDS 2.0 gives users low latency in terms of performance, i.e., under 100 microseconds storage latency measured inside virtual machines. It also gives users high throughput, at least one million IOPS per storage node, depending on the storage node’s hardware. There is a lot of performance room available in this system.
Who Uses It?
Around 80% of SDS 2.0 customers are new build deployments, with brand new purpose-built servers for being a StorPool storage node. The other 20% of customers have old storage hardware that they have used with a previous system, and they want to repurpose that. StorPool validates hardware on the component level, so it does not matter if customers use HP, IBM, or whatever they have used before. If the system matches the components in the compatibility list StorPool will run on it.
The minimum requirement is a gigabit ethernet network. The bare minimum is 10 gigabits or 10GBASE-T because of the higher latency of base-t. On the hardware compatibility list, there are also network interface cards that are supported. These are essentially two generations of Intel, Broadcom, etc., which means 98% of network interface cards are on that list.
SDS 2.0 is API controlled, so it fits well in DevOps use-cases such as dynamic provisioning. A lot of deployments of StorPool with tens of thousands of volumes and snapshots, each volume is a virtual disc or a virtual machine or a persistent volume in Kubernetes. In terms of data management capabilities, users can create many snapshots or have long chains of snapshots in snapshot-based backups, for example. Users can take these snapshots and send them to different locations.
StorPool gives each of its customers access to a monitoring dashboard and access to all of the metrics it collects. These are metrics in terms of the system’s user-visible behavior, per second IOPS, the latency of each virtual disc, and the underlying hardware that the solution is built on, so network, and CPUs and drivers underneath.
Conclusion
StorPool SDS 2.0 appears to be a highly scalable and efficient architecture. Storage operations are processed in parallel by many server instances and many system clients. There is no blocking between these components.
The architecture scales up inside each storage node so users can have a storage node with a single NVME drive and have a storage node with 24 NVME drives, for example, and scale-out with multiple storage nodes.
SDS 2.0 is one of the smallest three-server SSD systems starting at 500K IOPS and 0.2ms latency. It is a mature SDS technology and has been in production for over six years.