Zerto‘s Resilience platform protects and mobilizes applications, providing continuous data protection to those applications no matter where they are within an IT landscape. It delivers an uninterrupted bundle of disaster recovery, backup, and cloud mobility into a scalable platform for end-users.
Its next-gen solution has built on its public cloud offerings giving users the ability to mobilize workloads to, from, and between clouds. The next-gen solution adds journals, enhanced partner offerings, and more.
Zerto Showcased its updated system at Cloud Field Day 8.
Journal Based Recovery
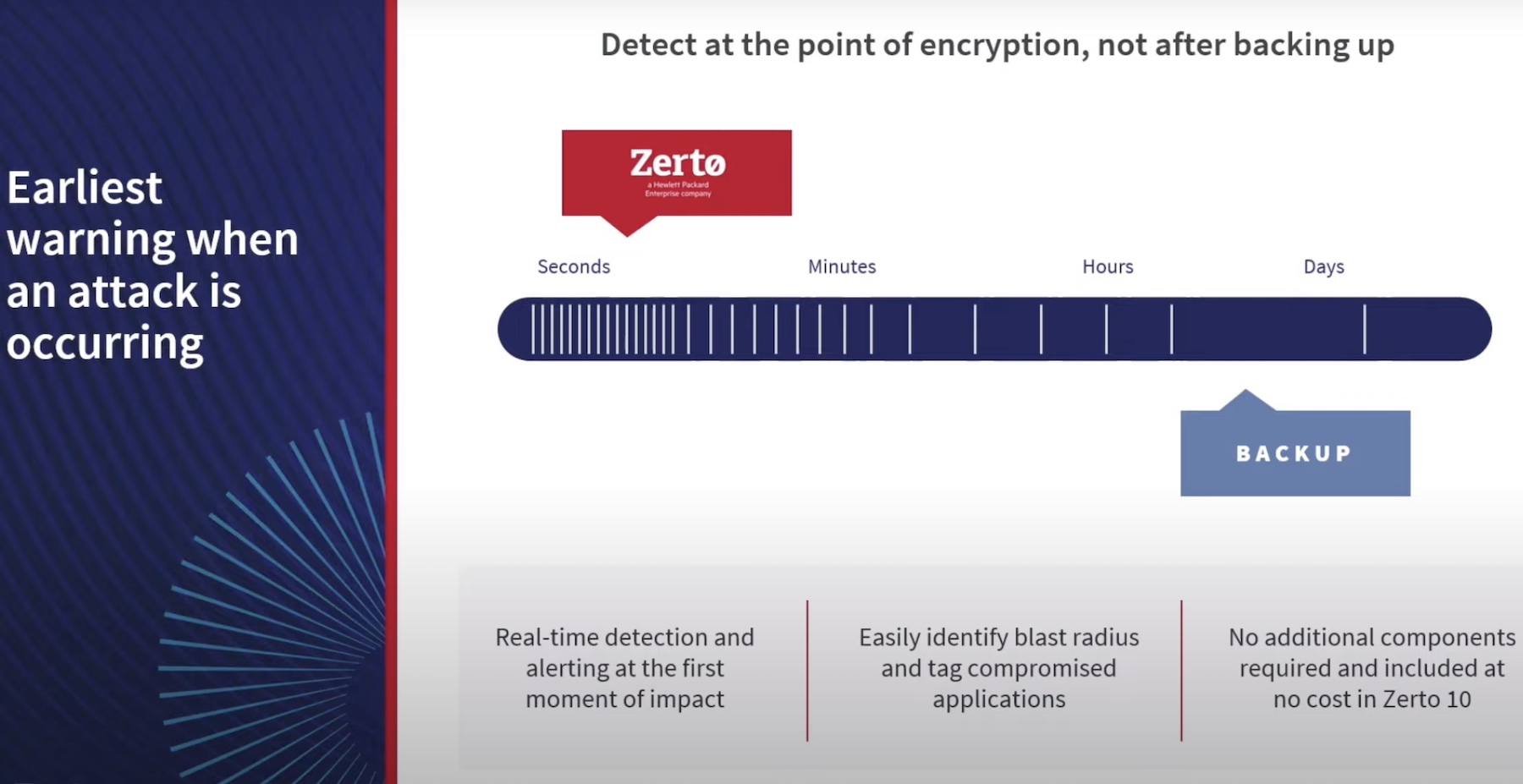
Zerto’s journal is a list of checkpoints that users can recover back to. How does the data get into that list? The system does it by using ‘always on replication’.
What does this mean? A VM starts writing IO blocks, and while it is doing that, those blocks are copied, compressed, and sent over to a virtual replication appliance – scale-out architecture that protects and replicates all of those changes. Those changes are stored in a journal, which is essentially a list of blocks, and between those blocks are placed checkpoints. The journal generates these checkpoints in-flight every five seconds. A user can recover their system to any one of those checkpoints in time.
For example, if ransomware hits a company at 4.59 pm and 56 seconds, the user can rewind to the previous checkpoint before the attack started. They can go back five seconds in time with increments of one second. The system can rewind an entire site, an application, a single VM, or even files. Because the journal is a continuous application, it can recover files created three minutes ago and deleted five seconds ago.
The journal’s time snapshot can be in increments of a minimum of an hour and up to a maximum of 30 days history, as written into its SLA. As soon as the block is older than its SLA, it gets pushed off to a replication disc, and the journal enters changes into a new block.
Each VM gets its own journal, and each journal is entirely configurable so that users can add a time-bound history to it. The user can add limits based on size, as well as time. Zerto also built-in bit-mapping designed to cope with surges of higher latency.
Delivering continuous availability, data protection, and mobility across all of those different clouds gives users the flexibility to decide where they want their workloads, at what time based on requirements, such as cost, latency, and availability.
Cloud Support
Zerto has a network of over 450 managed service providers (MSPs) that it supports. It also supports on-prem environments, VMware, Hyper-V, AWS, and Microsoft Azure, giving users mobility and disaster recovery across a range of public clouds.
Zerto supports VMware as a service, specifically those delivered by the IBM Cloud, Azure, and Google cloud. Azure has its Azure VMware solution, which is completely Zerto supported. It supports Google Cloud VMware, showcased at Tech Field Day 21.
However, VMware Cloud on AWS is not supported yet. That has to do with how it is deployed right now, it is very locked down, and Zerto needs a little more access and integration into both the hypervisors and vCenter. Zerto is working with VMware to see how it can be part of that ecosystem.
Microsoft Azure
In Azure, Zerto doesn’t integrate into hosts but uses all of the native offerings and services that Azure has available. This approach allows users to replicate workloads into Microsoft Azure.
Zerto has two components, the management component as the VM, and the VMware vRealize Automation (vRA) to replication appliance, which is a scale-out replication component. In Azure, utilizing that is impossible, so Zerto created its Zerto cloud appliance, which has parts of the vRA and z/VM built into it, storing everything where it needs storing in Azure.
For example, Zerto stores replicate disks into page blobs because that’s more cost-efficient. Zerto stores its journal data into block blobs because they are smaller and more efficient with journal data. Instances are created as soon as data recovery is needed on Azure, and data is moved from the page blobs into managed discs. Azure is architected so that the clone of the page blob data into the managed disc is almost instant. The only thing the Zerto application needs to do is call an API and make sure the data moves into the managed disc to start the VM.
Zerto can support replication between different Azure regions and replicate back again. The tight integration and the automation orchestration deliver a recovery time objective (RTO) similar to what can be achieved from a VMware to VMware or on-prem to on-prem environment because continuous data protection gives you those Recovery Point Objective (RPO) seconds. The automation and orchestration give you those RTOs of minutes.
Zerto integrates its application into Azure utilizing two native Azure services, Azures Queues, and Azure VM Skillsets. VM Skillsets allows users to scale based on a certain threshold of work in a queue. As soon as failover is initiated, Zerto places all IO and the work to be done, all of the data from the journal, into an Azure queue.
The Azure VM skillsets will monitor that queue and start deploying workers that write that data into the replica disc as it needs to. The system begins with zero workers, and as soon as more work hits that queue, Zerto can scale up and use those Azure skillsets. That allows Zerto to scale using the way that Azure has intended the VM skillset and the way cloud wants users to scale by using their native services.

AWS
In AWS, there are different services, a different model, and different APIs. Zerto does replication from an on-prem environment into AWS, but instead of storing it in blobs or discs. The system stores the replication on S3 objects or S3 containers. As soon as the user initiates a failover, Zerto starts importing that data from S3 containers into EVS volumes making sure the instances are created in the right order with everything needed from a DR perspective or a migration perspective.
In AWS, Zerto had to scale a different way because it doesn’t know the cloud hosts. It did that using Z-Importer. It built its scale-out system because it started using the AWS APIs to import the data from S3, but it didn’t scale well enough and wasn’t fast enough.
Together with AWS, Zerto built its APIs based on the data and volumes in the S3 bucket. Users start Z-Importer instances; all orchestrated automatically that will do the import. As soon as the imports are done, those instances are destroyed, and the data is available in AWS S3.
Conclusion
The core of what Zerto does is continuous data protection, a combination of always-on relocation, journal-based recovery, application consistency grouping, and long-term retention across on-prem and public cloud, making it a strong contender for DR. However, Zerto’s DR system is much more than just disaster recovery; it’s a reasonably failsafe system to protect data, run network tests, and more. Not only that, but it is available on-prem, on public cloud, through MSPs, and truly embraces almost every network environment.