Enterprises are bullish on GenAI, but nobody can quite figure out how to tackle implementation at a global scale. With persistent problems like runaway costs of infrastructure, growing number of inferences, and an ongoing talent shortage adding to their predicament, many companies are falling by the wayside.
At the recent AI Field Day event in California, one company, Kamiwaza, introduced an open-source stack designed to get GenAI to scale elastically. The Kamiwaza stack lets companies deploy AI anywhere, from cloud to core to the edge, efficiently, without paying unfeasible costs.
“We are here to help enterprise get to a trillion inferences a day, and that’s going to be the inflection point for the 5th industrial revolution,” declares Luke Norris, CEO of Kamiwaza.
“Kamiwaza” translates as “superhuman”, and their mission is to deliver superhuman AI capabilities to enterprises. At first, it sounds like a marketing pitch cut from the cloth same as many others, except it isn’t. Kamiwaza has a smart and working solution to a very thorny problem.
The Uncomfortable Reality of Developing and Running GenAI
The cost of developing and implementing GenAI at a global scale is extraordinarily high. A hardware stack made up of discrete components that can handle training at scale and 100,000 inference calls a second, alone costs over millions.
Compounding the problem, the AI process is notoriously complex and costly. The operation is split into three parts – data, model and deployment. AI models are trained on mountains of data. The models ingest terabytes of data – texts, words, images – every day, as part of the learning process. In a distributed ecosystem, this data resides in disparate platforms spanning locations across the globe.
Sourcing datasets from these scattered addresses is fraught with security concerns. Access management and control is mission-critical to the security and integrity of the data.
The awareness has steered many enterprises towards private AI. “One of the things we found is that enterprises, for production use cases where there’s “keys to the kingdom” data, they are reluctant to just push that off into the cloud. They’re still trying to control their own destiny to a certain extent,” says Matt Wallace, Co-Founder and CTO.
“If you want to do it on your own horsepower, you’re stuck between making it work as one-off and getting to true production scale,” he adds.
Feeding astronomical amounts of data into the inference engine is another challenge. AI inference is computationally intensive, and inferences happen continually. The models process millions of user queries every day, and even the simplest of prompts can set off scores of inferences. “All those things add up to a lot more inference than people expect, and it becomes very expensive very quickly,” he points out.
Adoption has been sluggish for another critical reason – lack of in-house expertise. “If you are just a general enterprise and you’re trying to train a net new model, you’re absolutely in the wrong field,” Norris says.
There are approximately 30 million developers and 300,000 ML engineers, coupled with a handful researchers, in the world that truly know the technology inside out, and are credited to building a GPT4-level model, Menlo estimates. To average organizations, these professionals are out of bounds because they’re already taken up by the IT powerhouses.
Proximity-Based Processing with Kamiwaza
Kamiwaza offers a holistic GenAI stack that until recently constituted 25 open-source packages designed to work at different stages of the AI pipeline. But to specifically address the barriers around scaling and deployment of private GenAI, Kamiwaza added two novel solutions – an inference mesh, and a distributed data engine, to perform what is called proximity-based data processing.
Kamiwaza provides a distributed framework powered by Ray, for large-scale inferencing, scalable from small edge locations to enterprise productions, on owned hardware or in the cloud.
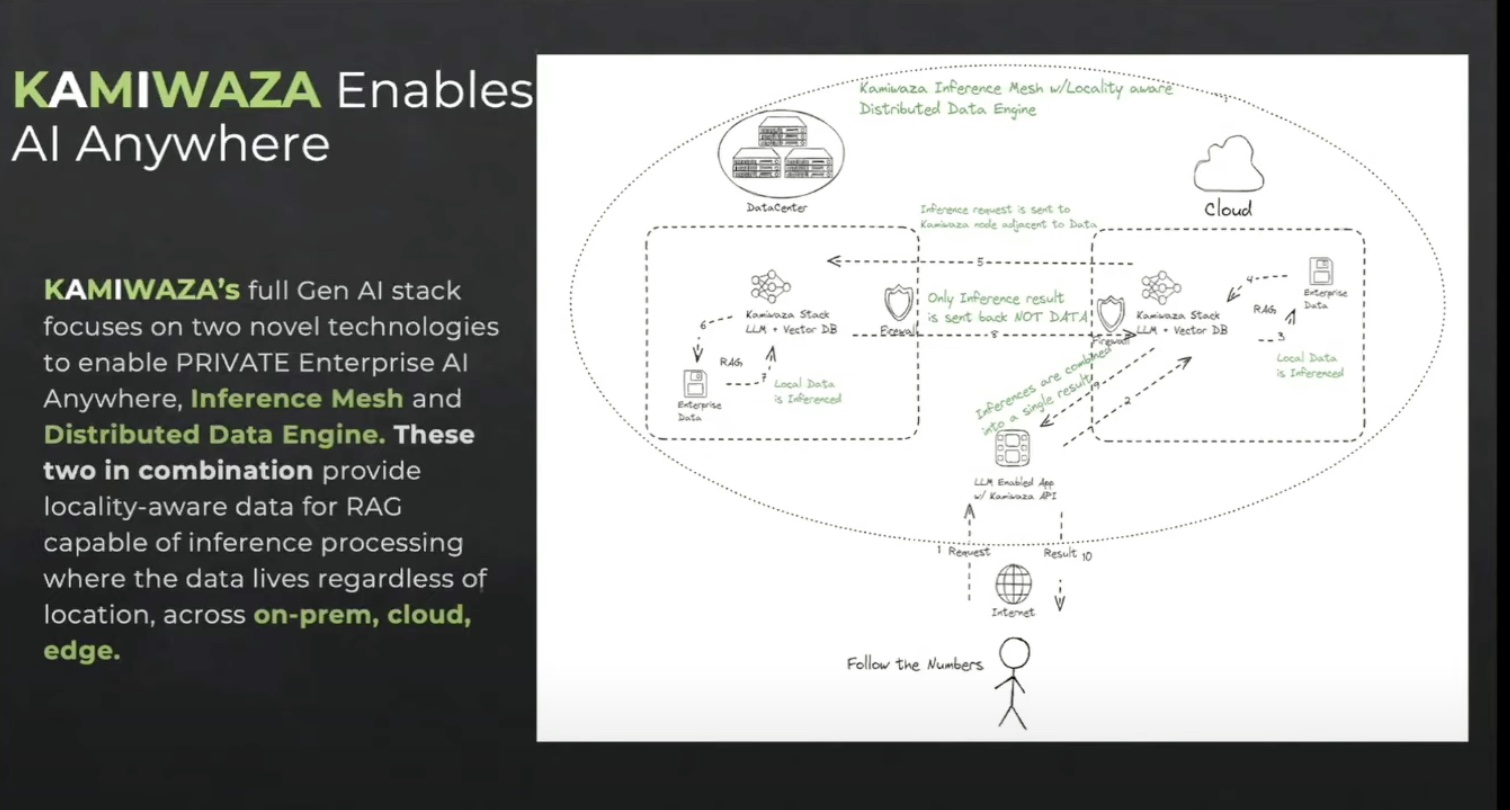
The Kamiwaza stack is deployed in all locations from cloud to core and the edge. “It’s an installable stack that kickstarts out of Docker,” says Wallace.
When an inference request comes through from a certain location, it is routed via APIs to the Kamiwaza node sitting in the same location as the data that is required to process it. The inference mesh and the location-aware data engine retrieve the data and process the request locally.
Just the inference result is streamed back to the user, while the data remains in place. For a more efficient result, several inferences are bundled into one result.
Kamiwaza provides comprehensive access management features with built-in OUTH and SAML for authorization by source.
Intel CPUs are a mainstay for inferencing workloads. Wallace informs that the Kamiwaza stack is fully compatible with Intel processors, as well as with bigger GPUs, and specialized ASICs.
Kamiwaza consumes very little power. Running the community edition on his laptop, Wallace tells that it consumes less than a single core for constant usage.“It’s a handful of containers, but they’re only using very thin time slices. Like on a MacBook, it probably consumes at most 20 or 30% in the background, so pretty lightweight.”
To see Kamiwaza live in action, be sure to check out the demo session in the latter half of Kamiwaza’s presentation with Intel from the AI Field Day event.



