The ability to roll back changes has revolutionized the way that we troubleshoot. When someone makes a change to their Windows computer that does something unexpected, the first troubleshooting step now is to use the rollback feature to go back to when the system was operating correctly. It’s a feature that saved me more times than I care to mention.
Ever since it became a marquee feature in Windows XP1, it has become an integral part of the troubleshooting process. Install an update that broke something? Rollback to the last time it worked. System won’t restart after a change? Choose Last Known Good Configuration from the startup menu. Not sure if you’re about to do something that is going to set everything on fire? Set a System Restore point and hack away with the knowledge that you’re protected.
Steady State of Change
Rolling back changes isn’t just for desktops. VMware has a feature that takes snapshots of a virtual machine for changes to allow you to go back to a working configuration. Storage systems do the same thing to ensure that data isn’t lost or that you can create a checkpoint to take a backup while you’re in the middle of something else. These systems have all figured out the importance of confirming changes and allowing users to go back in time if things don’t work out the way they want. It’s something that everyone has figured out – except for the networking team.

The reasons why have more to do with the system than the device. When you make changes to a PC or a VM or a SAN, the impact is usually limited to the individual device. Installing an update on your PC doesn’t affect your wireless access point. However, the network changes impact the entire state of everything. Making a change to the administrative distance or other route metrics means that the whole routing table needs to be recalculated. Paths could change drastically when taking additional information into account because of little tweaks. It’s even best practice to make routing changes and then give the network hours or even days to settle down and become stable before poking it again. That makes it even harder to trace down problems and resolve them. Where did this even start in the first place?
Fantastic Voyage
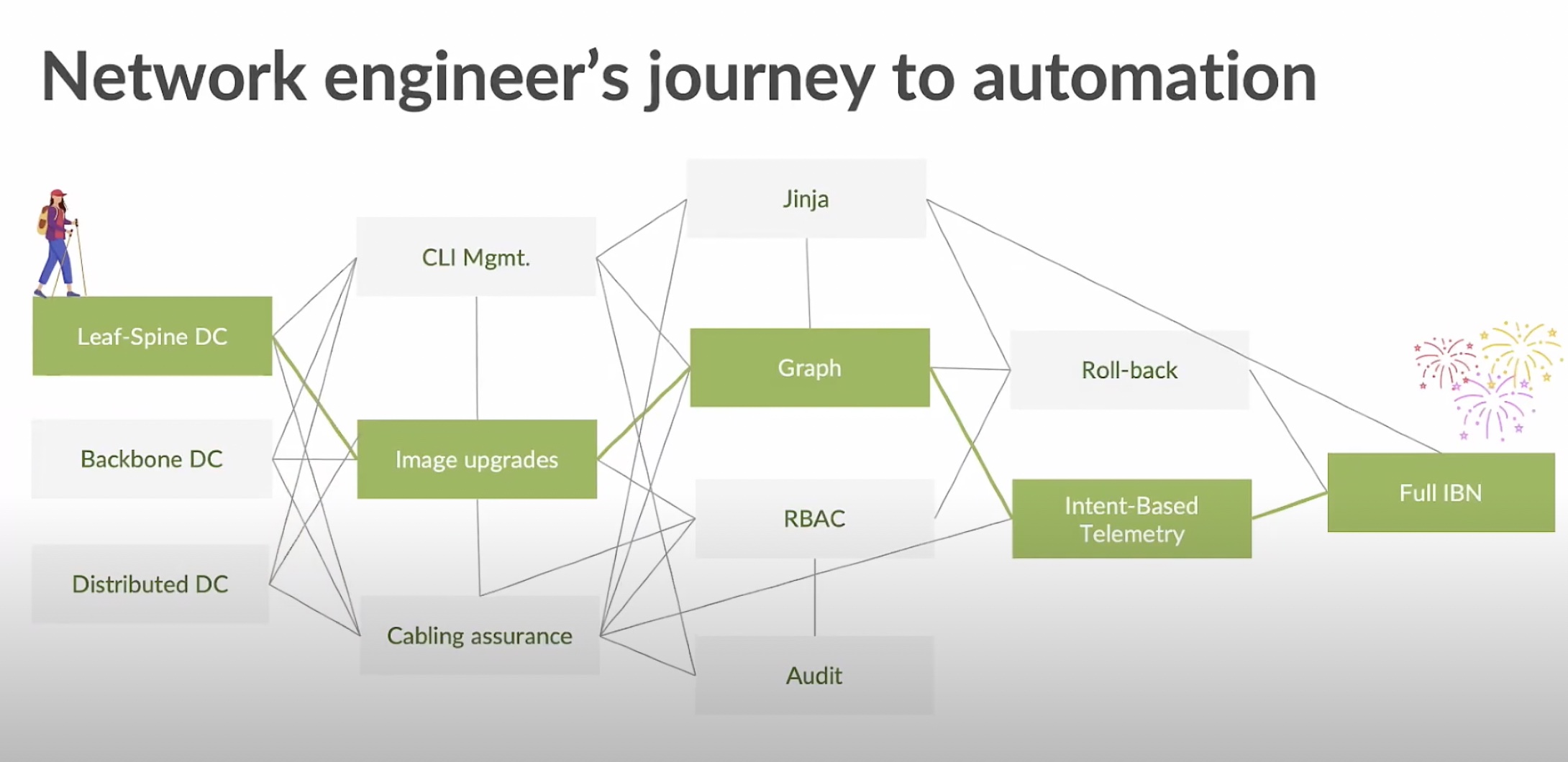
During the recent Networking Field Day 23 event, I had the opportunity to get a presentation from Apstra. They’ve been doing a great job building up an intent-based networking platform that enables automation across the entire enterprise. They have smart people solving problems that engineers and operations folks have every day. Imagine my delight when I saw them start talking about the idea of a network-wide rollback for bad changes:
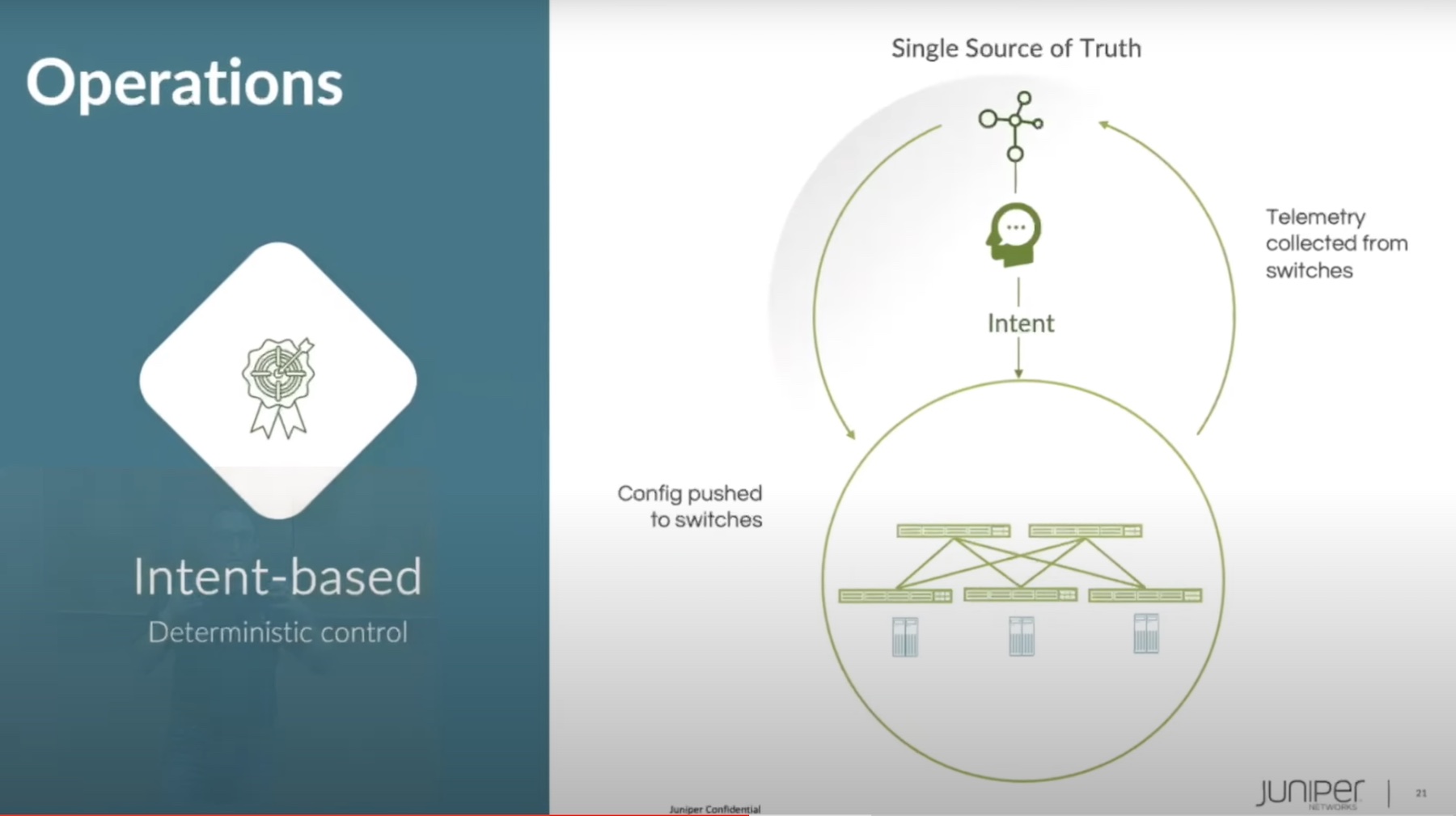
I was quite literally hopping up and down in my chair when I saw this section. The idea is sound enough when you think about it. Because we can draw a graph of the network and understand pathways and other important data, we can also store that graph somewhere. We also have access to the configuration data on each of the network devices, especially if we’re smart. We’re using a declarative programming model from a central location instead of just opening the CLI on a device hacking changes directly into RAM. If we have the configuration of all the devices and the network graph to prove stability and operations, we can write it all to a database and create a Known Good State.
Now, let’s say we make a change. Something small or unimportant. Maybe we’re at the end of the year, and we’re playing with something we saw online to push the network’s performance a little harder and get an excellent mark on our year-end review. Except the change has some effects we weren’t expecting; a routing table interaction on the other side of the network, perhaps. Now we’re in deep trouble.
The whole network will be reconfiguring and be unstable when we really shouldn’t have been making changes at all. People will get called in to fix something we shouldn’t have been doing in the first place.
The above scenario plays out very differently with Apstra Time Voyager. Because we knew the Known Good State of the network before we started making changes, we have a fallback. If the change does something wildly unexpected, we just need to hop over to our console window and roll back the whole network to the Last Known Good Configuration. Apstra takes care of pushing the right commands to the networking devices and getting rid of our unintended upgrades. The network is stable, no one’s pager goes off during Christmas dinner, and we breathe a sigh of relief that we’re not going to get written up for playing with fire in a change freeze.
Bringing It All Together
Apstra has a ton of great features on the platform. So many that Juniper decided to snap them up in December 2020. This combination of top-tier network operating system and rich SDN feature set will drive innovation in the industry for years to come. Juniper already had a robust configuration checking system per device. Imagine that at the scale of an entire enterprise network! I can’t wait to see how these two companies integrate the Apstra technology with Juniper’s track record of great hardware.
For more information about Apstra and their SDN technologies, make sure you check out their website at http://Apstra.com.
- It technically came out in Windows ME, but I refuse to give that OS credit for anything. ??