Once upon a time, there was the enterprise data warehouse. The idea seemed to make sense: put all the data you want to analyze in one place, and then you can do all the analysis you might ever want to do. Economies of scale will make analysis easier and cheaper than having to figure out how to look at data sitting in lots of little piles scattered all over the place, which is messy and inefficient. The elegance of a single, optimized solution was very appealing.
And so we built massive monuments to data science. More and more data was sucked into the data warehouse, with complex ETL jobs to change it into the One True Format the data warehouse required. Data flowed into the data warehouse from all over the organization and a future of endless insights gleaned from Big Data seemed inevitable.
But there was a problem.
New datasets kept getting created outside of the data warehouse. New applications would be written, and they would generate data, but that data would sit close to the application. Sometime later we’d decide that we needed to include this new data in our analysis, but that analysis had to be done on data in the data warehouse. To get it there we’d spin up a project to write ETL jobs and make copies of the data and attempt to massage it into the One True Data Warehouse Format. And then we’d do it all again for the next app, and the one after that.
And maybe our company would acquire another one, and then we’d have two data warehouses. Or a business unit would decide that they needed to do things a bit differently, so they’d create another data warehouse that was also, confusingly, an enterprise data warehouse.
While the theory seemed sound, in practice we struggled to achieve the vision of a single unifying source of data for analysis. And rather than converging towards our ideal vision, the world seemed to only get messier, more distributed. We now have multi- and hybrid-cloud as well as public and private clouds, and the advent of IoT has exploded into edge computing as well.
The World Changed
We weren’t wrong to want a data warehouse, it’s just that the world around us continued to change, and what was once an appropriate and useful choice became… well, less so.
As storage media got cheaper and faster, we generated and stored more data. The creation of data is massively distributed, and there simply isn’t enough bandwidth in the world to consolidate it all into a single place.
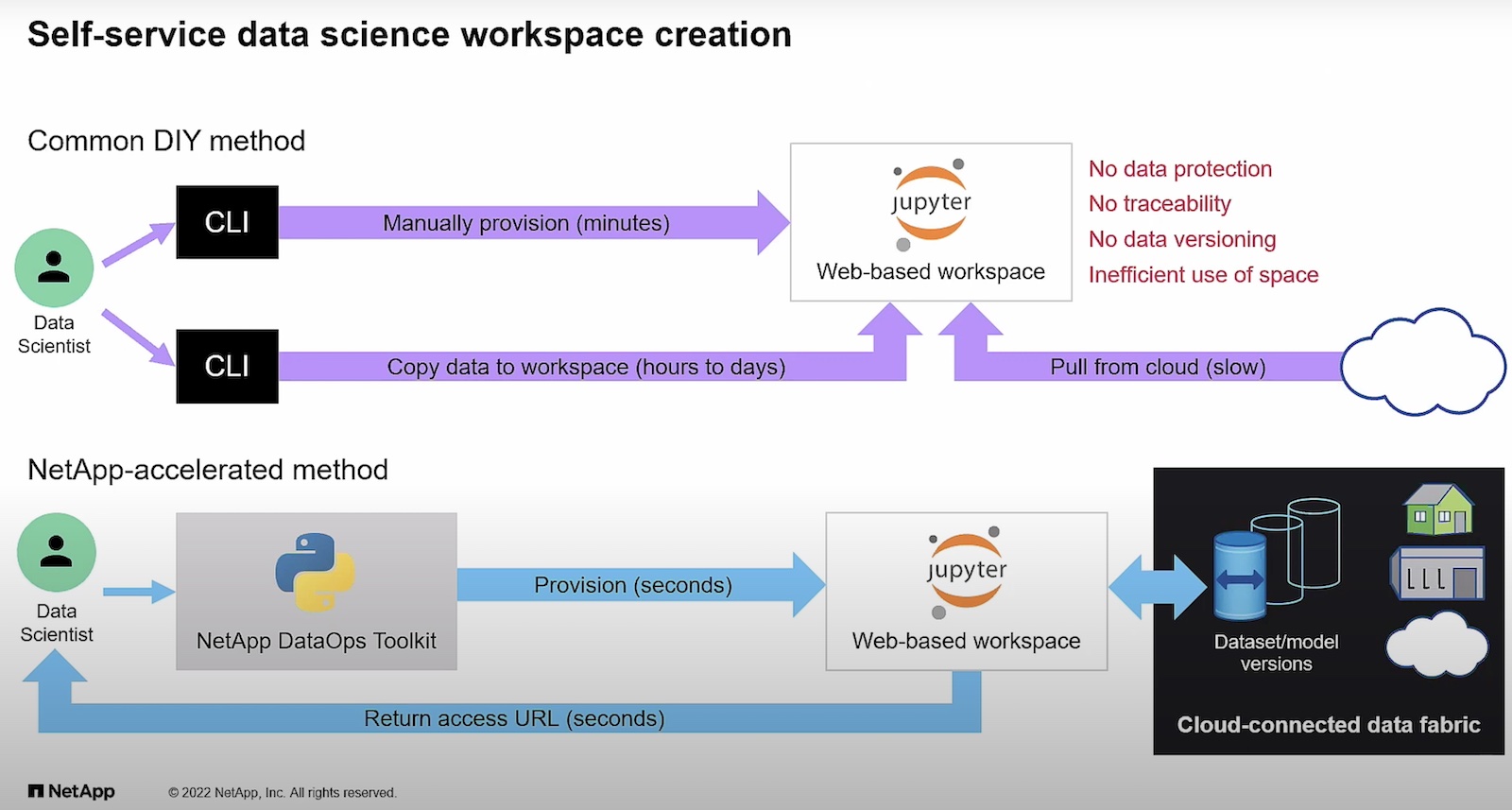
Data has inertia; moving it takes a lot of effort, and the more data there is, the harder it is to move it around. Instead of moving large datasets around, it is far easier to move compute workloads closer to the large datasets.
And not all data has the same value. Financial transaction data is of little use to a machine-learning image classifier. Logging data from five years ago doesn’t help diagnose a problem today.
Rather than trying to impose a single, perfect structure over all data, we need to embrace the inherent complexity of modern IT. There are tradeoffs to be made, and what we decide is the right approach today may well be the wrong approach tomorrow. Not only must we embrace complexity, we must also embrace change.
But this creates a new problem: how do we manage a complex and dynamic ecosystem of disparate datasets and applications? The number and volume of datasets required to support a modern IT ecosystem is beyond the comprehension of any single human mind.
Data Orchestration
Making sure the right data is in the right places at the right times is a complex exercise. Trying to avoid this complexity is part of what gave us data warehouses in the first place, but with the power of modern computing, what were once intractable problems are now at least manageable if not simple.
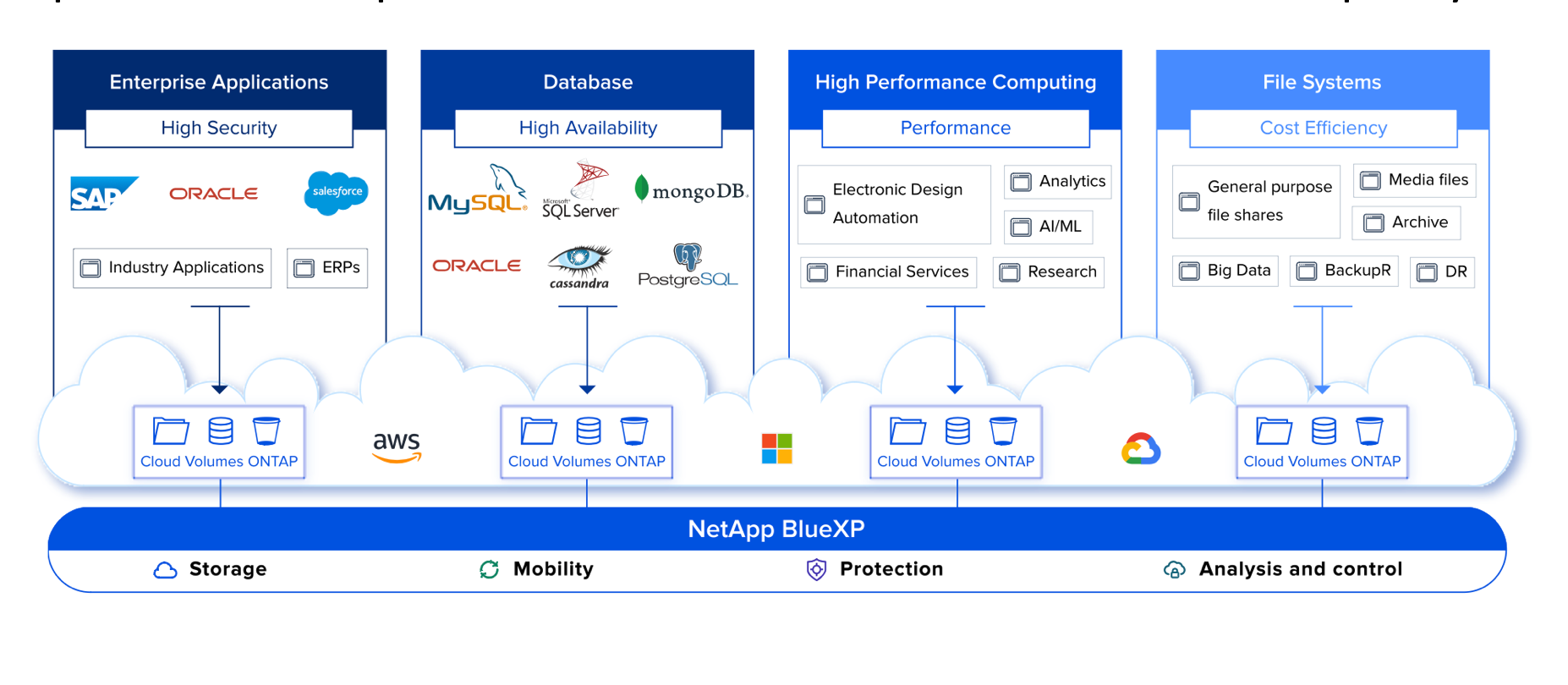
Data orchestration helps us to strike a balance between consolidating data for reuse by multiple analyses and leaving data in place so it can be analyzed where it lives. We can intelligently connect data to the applications that need it, or move large datasets if we have to, but always with a clear reason for doing so.
Rather than trying to reduce the world to a simplistic “One Size Fits All” world of either single data warehouse or no consolidation at all, we can use modern data orchestration approaches to make good tradeoffs.
Using data orchestration tools also provide a wealth of secondary benefits: automation of repetitive tasks, audit trails for tracing data lineage, security controls to keep sensitive data safe while reducing friction for authorized personnel. Data orchestration helps us to see data as part of an ever-changing ecosystem rather than a single monolithic structure or an impenetrable fog.
For we must also keep in mind that whatever we choose to do today will not be the best choice later. Rather than cling to outdated decisions, we should embrace flexibility so that we can more easily respond to the ever-changing demands of the modern world.
NetApp’s Approach
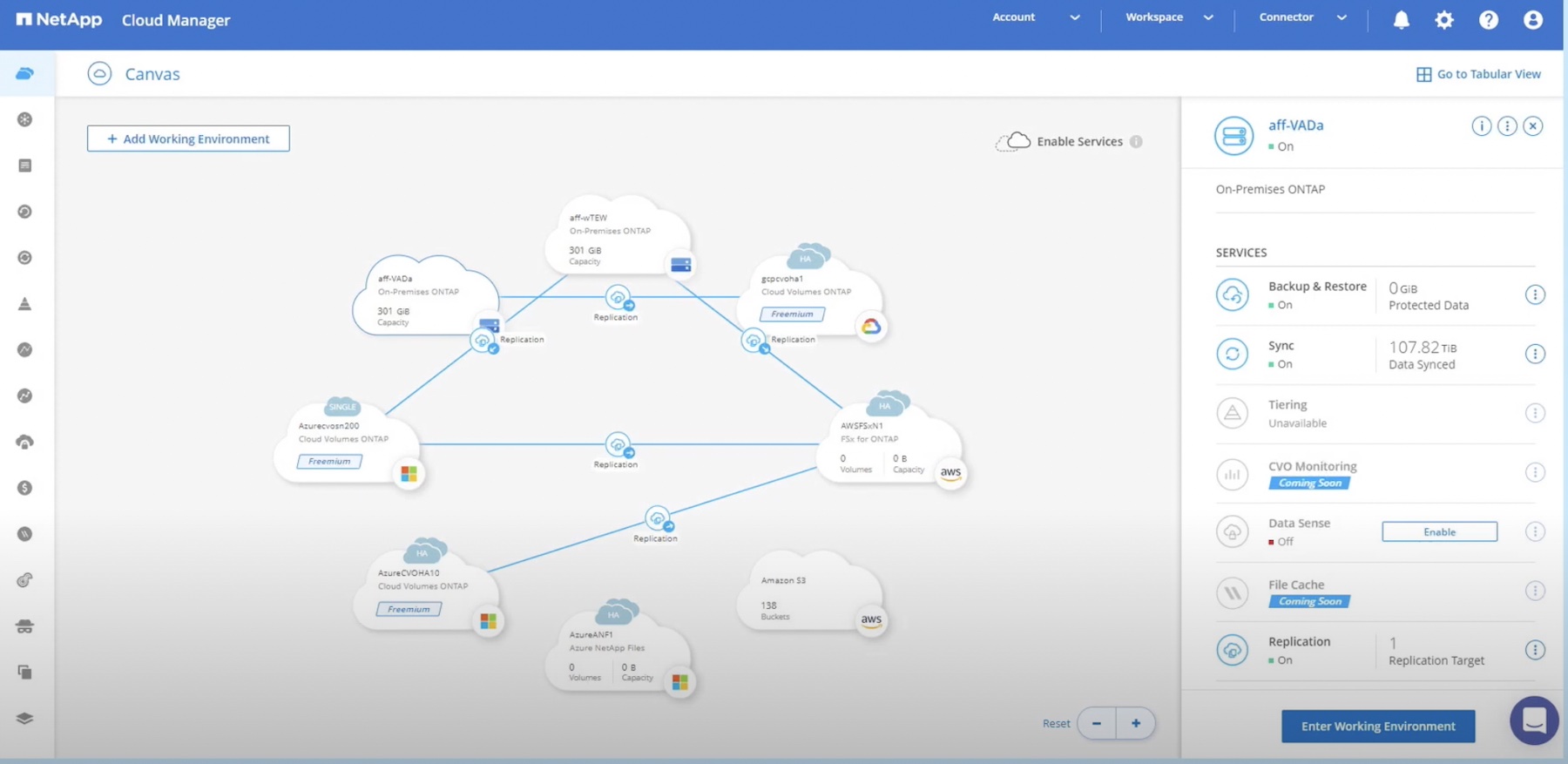
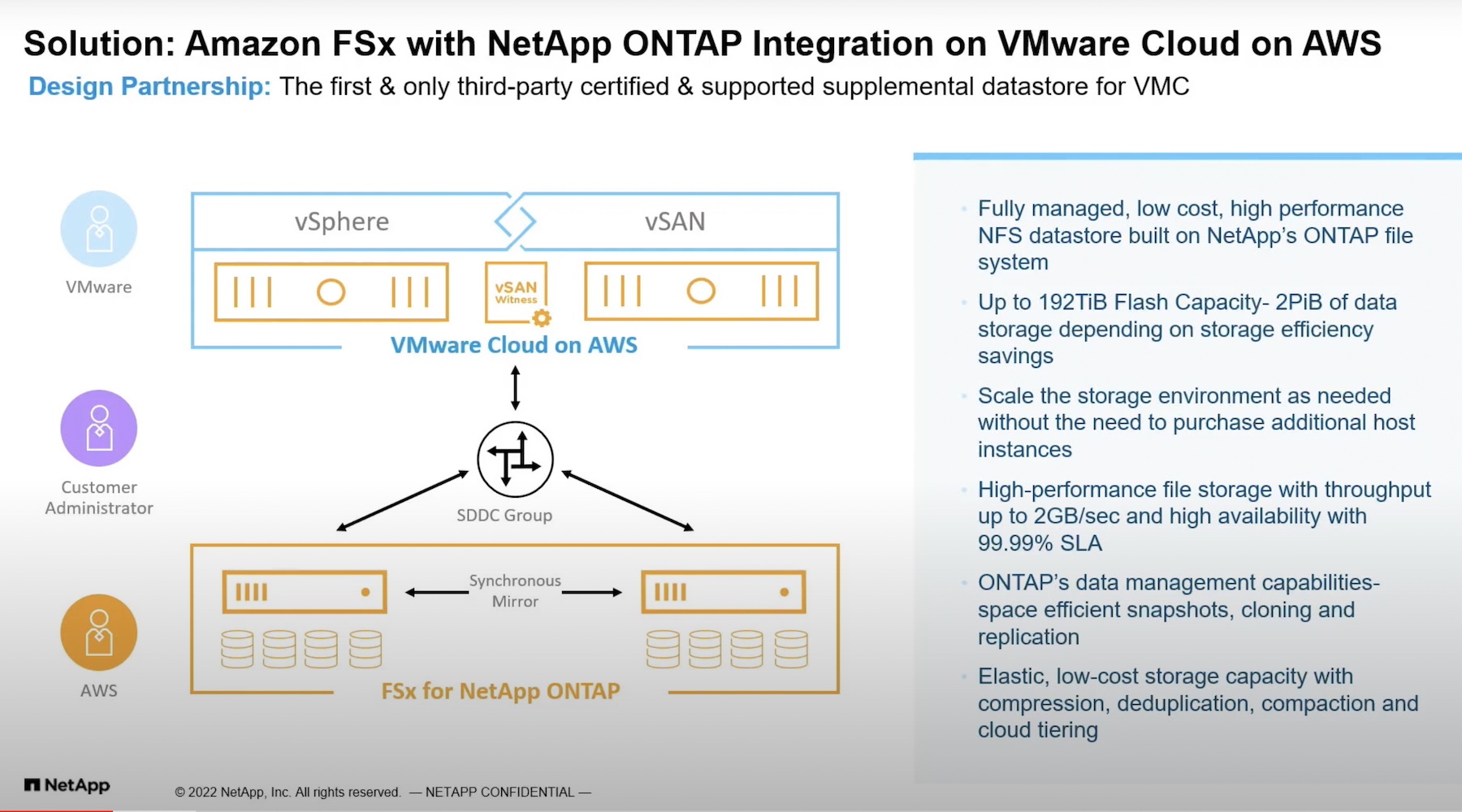
NetApp has been talking about its Data Fabric concept for some time now. It started with the idea of data portability: connect your NetApp storage to different applications by putting your NetApp array in a colocation facility and then use Azure ExpressRoute, AWS Direct Connect, or similar to connect to cloud applications, while also connecting to your regular enterprise applications.
For me, the physical location of the array is less important than the fact that the operations look the same regardless of which application I’m connecting to. This operational aspect became even more important when NetApp added the Cloud Volumes Service to its offerings: NetApp storage, only as-a-service that operates just like other NetApp storage.
By choosing a common operating model based on NetApp storage, customers could automate using the one target set of APIs, which provides a lot of flexibility. If you decided to move a set of data from on-site NetApp storage into the cloud, or vice versa, it wouldn’t require major modifications to the automation systems that might slow you down, or kill the project for being too hard.
By preserving optionality businesses can respond to change more effectively, which means they can react more effectively to the rapidly changing world around them. Being wrong no longer incurs a huge cost, so you can run more experiments, and quickly adjust course when you discover new information.
NetApp has further plans that build on its existing automation approach to add a layer of abstraction, much as its Kubernetes Service provides an abstraction for where and how applications run. It’s worth keeping an eye on NetApp’s Cloud offerings to see how their thinking has translated into products so far, and where their vision for data management leads.