Data is proliferating at an unfathomable speed in modern organizations. This acceleration, triggered by the AI era, is making integration of data into decisions a winding and complex journey involving robust data management strategies. NetApp presented NetApp DataOps Toolkit at the AI Field Day event in Santa Clara, California which is built to solve the most pervasive and fundamental challenges around data operation for faster AI deployment and better data innovation.
Stumbling Blocks in AI Data Management
Data management remains a constant challenge for businesses pursuing AI initiatives, and no matter where they are in the AI journey, difficulties around data related operations are felt across the board. Irrespective of the infrastructure modernization and technology overhauls, data management to this day hasn’t attained the level of sophisticated required to seamlessly adopt AI. Several obstacles lie in the way of that.
In practice, data management is a multi-step process that involves integrating datasets coming in from multiple sources, migrating data across platforms, extraction of valuable data from bulk data, storing that data to train AI models and data governance. This involves high levels of complexity in the context of DIY infrastructures, constantly evolving software stacks and rapidly scaling AI projects. Combatting these encumbrances and have data available and accessible is an uphill battle that data scientists have to fight at work daily and the boundaries and lack of communication between teams is anything but helpful to that.
NetApp Putting Existing Storage Technologies to Work to Simplify AI Data Management
Under the hood, NetApp has a multitude of solutions that could help with AI data management. Technologies like Snapshot which is a data versioning technology, FlexClone, a data cloning solution and Data Fabric, a cloud data management solution for easy data movement, NetApp saw, could prove valuable in solving the data operations and storage challenges data engineers and scientists face at work every day.
NetApp is collaborating with appliedAI, an AI accelerator company in Europe as well as several other AI consultancies to make some of its AI data management tools and solutions accessible to data scientists and data engineers in organizations worldwide. Taking some of the storage capabilities and repackaging them into an easy-to-consume solution, NetOps designed NetApp DataOps Toolkit (formerly Data Science Toolkit) getting these existing technologies to solve some of the challenges in data management for data scientists.
NetApp DataOps Toolkit, a Python Module That Makes Data Management Tasks Simple
At the AI Field Day event in California, NetApp made an interesting presentation where they brought in industry experts from inside NetApp to talk about their experiences with data management and for the audience to hear from their mouth what the real challenges are at the ground level. Dave Arnette, Principal Technical Marketing Engineer with NetApp’s AI Solutions team gave a brief intro of NetApp and the data management problems specific to AI that it addresses to mitigate with the DataOps Toolkit. Following that, Max Amende, Solution Engineer and AI Specialist at NetApp shared his experience and takeaways about AI data operations working as a data scientist before.
For the rest of the presentation, Mike Oglesby, Senior Technical Marketing Engineer, NetApp and his colleagues talked about the NetApp DataOps Toolkit that makes it simple for data scientists to perform all data management tasks while detailing some of the technologies behind it and its capabilities, and explaining how it can make data management at scale easier and simpler for data scientists.
A simple Python library designed for data engineers, developers and ML engineers keeping in mind their familiarity with Python, the DataOps Toolkit is an open-source, easy to install and free to use tool for anybody who has a NetApp storage subscription. Available in two versions, the NetApp DataOps Toolkit for traditional environments supports VM and bare-metal and the one for Kubernetes comes with support specifically for Kubernetes-based environments and some additional features.
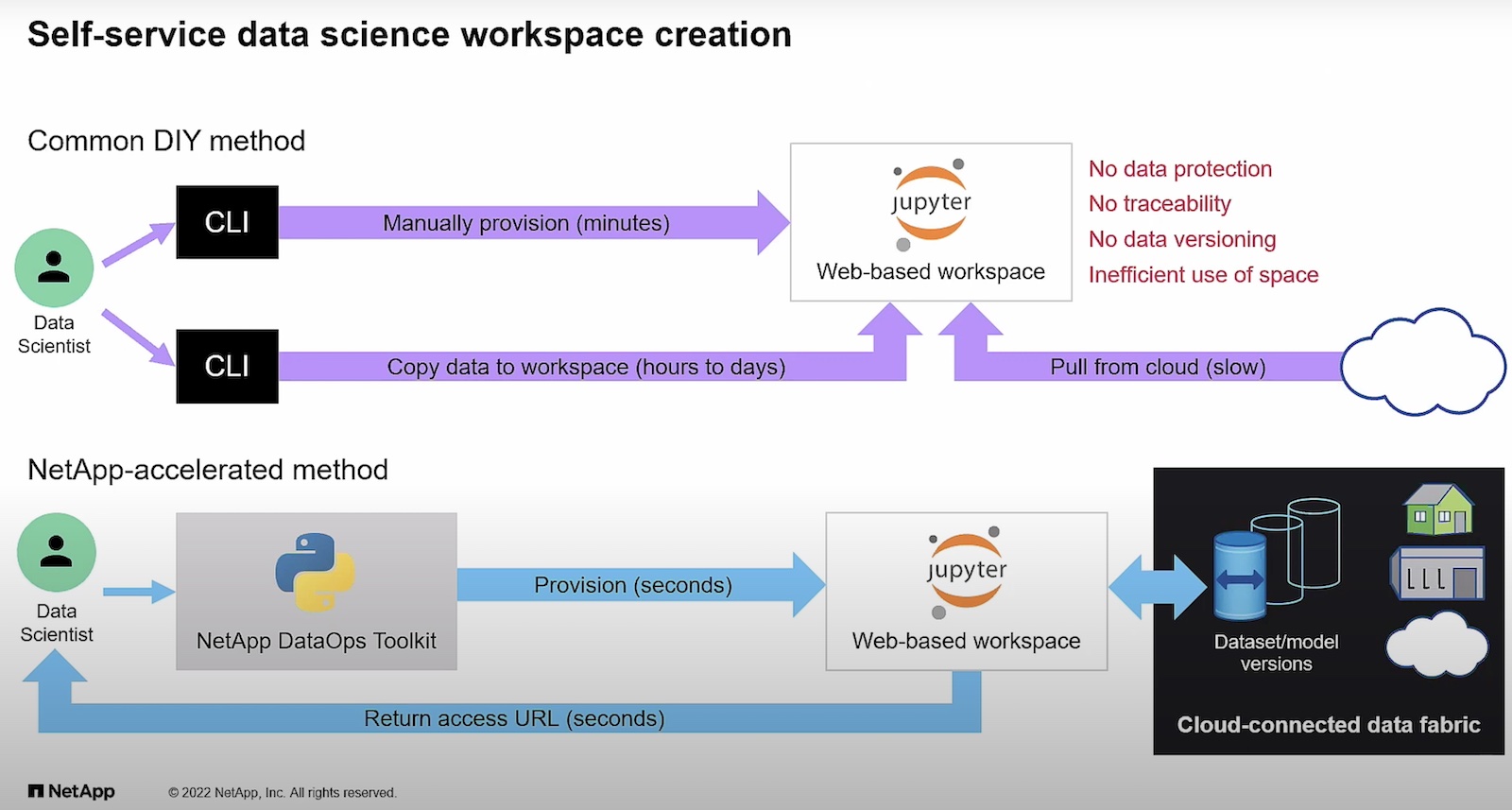
In a self-service fashion, the DataOps Toolkit creates workspaces of any size within seconds with just a single command. In a similar way workspaces can be created on Kubernetes with the DataOps Toolkit for Kubernetes – only here users can even pull up their data into the workspace from any Jupiter Notebook or Python workflow using just an URL. Both the versions are backed by NetApp’s persistent storage and work with TensorFlow and PyTorch and similar frameworks, .
Provisioning can be done in seconds with just a function call with inference servers like the Triton Inference Server from their partner, NVIDIA. The NetApp DataOps Toolkit snapshots data for traceability which based on the policy and policy age can be automatically tiered off into a cold data archive for a certain period. Thus, instead of having to save them in the high-performance store, they can be economically archived for compliance and recalled from backup when required.
Final Verdict
To solve the majority of challenges around AI data management, a solution has to first and foremost, make everyday data management tasks simpler and streamlined, and that the NetApp DataOps Toolkit does successfully with the addition of data storage support. With near-instantaneous and quick one-command provisioning, cloning and snapshotting, it makes it simple and easy for developers to manage, manipulate and store massive datasets . It’s a simple tool that any developer, data engineer or data scientist would be comfortable using, and one that aligns seamlessly with the universal enterprise vision of better data innovation, through easier data operation.
For more information on NetApp DataOps Toolkit, check out NetApp’s other presentations from the recent AI Field Day event.