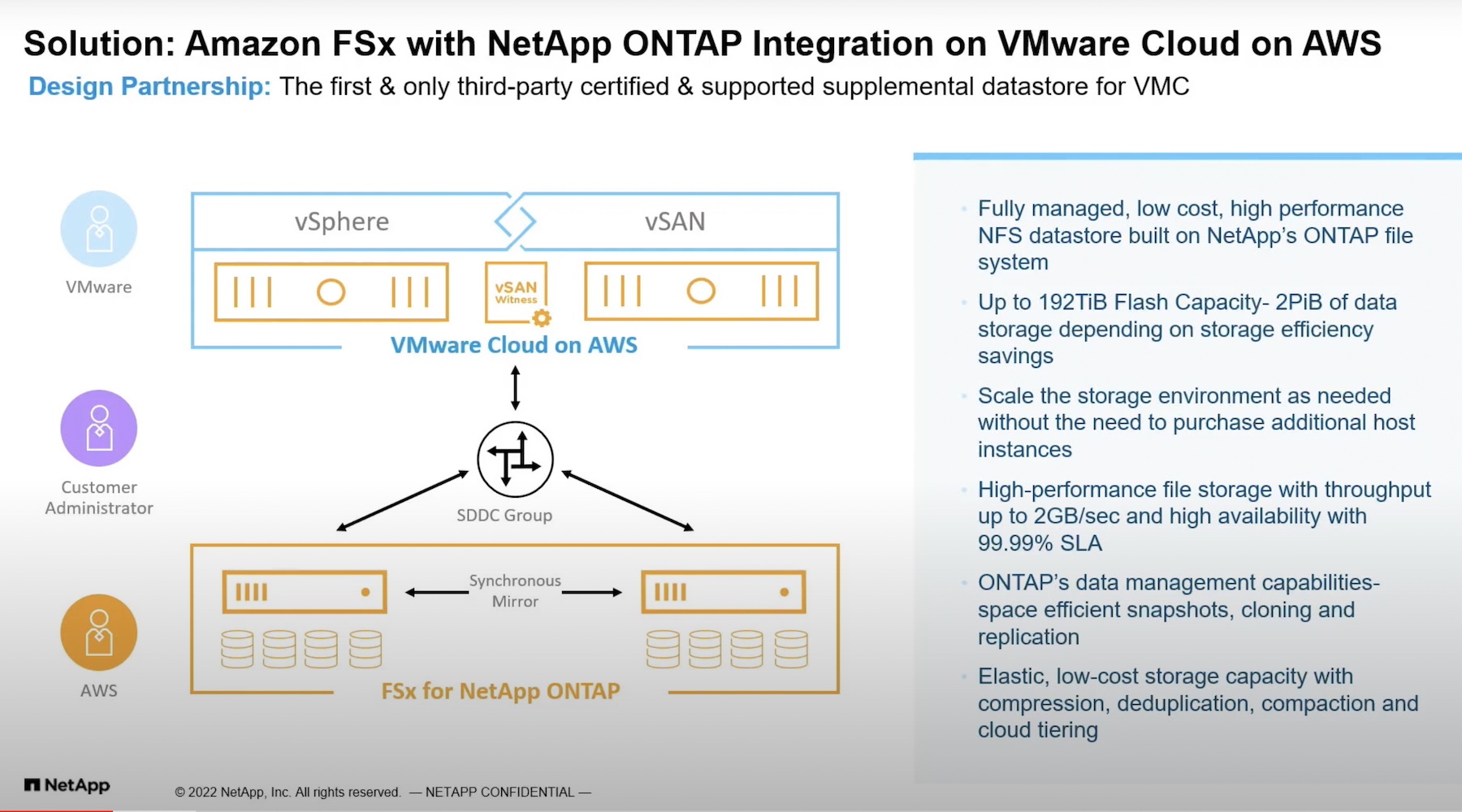
Introduction
Cloud has brought significant disruption to the IT landscape. Some technologies, like compute, have easily made the transition from an on-premises deployment to a cloud-based environment. Other technologies have struggled with the transition, such as networking and storage. New approaches and protocols had to be established to handle the multi-tenant environment and massive scale that the cloud operators require.
Churn and change have required establishing new standards of interacting with what exists in the cloud. By the NIST definition of a cloud environment, it must be self-service and consumption based. Creating a self-service interaction is a fundamental shift from the traditional silos that exist in an on-premises datacenter. Since the cloud is consumption based, there is a requirement that resources are allocated on demand and removed as well. Again, this is a complete change from a traditional datacenter approach where capacity is increased in a step-function as each wave of capital spending comes available.

While the cloud has brought significant changes and improvements, it does not mean that an ideal state of affairs has been reached. The public cloud vendors certainly have their shortcomings, and those gaps create opportunity for third-party vendors to bring new solutions to address customer demand. In this post, we will examine the current state of affairs in on-premises and cloud based storage, focusing on the two behemoths of the public cloud world, Amazon Web Services and Microsoft Azure. We will identify some gaps that exist in the current offerings and how NetApp is uniquely positioned to solve customer needs.
Traditional storage types on-prem
When it comes to on-premises storage, things have become standardized and often times stagnant. There are essentially three ways of presenting storage for consumption by an operating system: NFS, CIFS/SMB, and block. For the most part, block storage is presented to a single host, though it can be presented to multiple hosts provided they can work out access control on their own. A common example that most IT practitioners would recognize is the ESXi operating system from VMware. Each host in a cluster can be presented with block-based storage in the form of a LUN, and the operating systems use the VMFS file system to manage access to the storage among the various hosts in the cluster.
NFS (Network File System) and SMB (Server Message Block) present storage to operating systems as a shared file system across multiple hosts. NFS is most prevalent in Linux-based operating systems, where the NFS file system is mounted to the local file system as a directory. The applications on the local host do not need to know that the NFS mount is a remote file system, and they can treat the file system as a local one. SMB is most prevalent in Windows-based operating systems, and functions in a similar manner to NFS. There are some differences in the implementation and supported protocols, but at their core NFS and SMB are distributed file systems.
In the world of on-premises data centers, storage tends to be closely guarded by administrators. These bastions of the bit bucket are wary of change, knowing that if they fail in their mission, storage might be unavailable, or even worse, data might be lost. To protect their kingdom from harm, storage administrators have centralized their resources physically and partitioned management from other systems. Storage area networks were established to present block-based storage from massive arrays, and likewise ethernet networks were partitioned off to provide high speed access to NFS filers or SMB servers.
The centralization of storage combined with a leeriness of change created a situation where storage seemed inflexible and rigid. That could be good when viewed through the lens of consistency and compliance. Data was not lost. The system was reliable. But it was not good for the accelerating pace of application development and deployment. Whereas, developers found that compute and networking had become simple to consume, storage still appeared to be the laggard. Requests were slow to be completed, and sometimes outright denied. Support for new features, like containers or object-based storage, were always on the horizon, a mirage that never seemed any closer. And so developers began to flock to the cloud, where more storage was only an API call away.
Cloud storage types
Cloud-based storage retains the traditional formats of block-based and network-based. But an additional storage class was introduced, object-based storage, starting with the Simple Storage System (S3) from Amazon Web Services. In fact, it was the second service offered by AWS, the first being the Simple Queue Service (SQS). Object storage treats data as individual objects, each with a globally unique identifier and metadata about the object. Cloud-based storage needed to deal with massive scale and distribution across hundreds of physical nodes. Object based storage enabled that massive scale, with the only limitation being the unique identifier associated with the object. Object storage also includes built-in features like replication and versioning.
As public cloud providers began to build out their infrastructure, they deliberately moved away from traditional storage area networks and massive storage arrays from third-party vendors. Their preference was to build storage clusters from open-source or in-house software, and use white-labeled hardware. Control of the entire software and hardware stack reduced their operating costs, and enabled them to accelerate the development of new features in order to differentiate themselves.
The storage offerings in the cloud implement the core tenets of cloud computing. Each tenet had specific impacts on the way that cloud storage functions.
Programmatic access
Storage from the cloud has be available in a self-service model. All management operations of the storage must be available through an API so that they can be addressed programmatically. This includes the creation of new storage, the expansion of existing storage, and the deletion of retired storage. It also must be possible to monitor the status of storage, including availability, performance, and consumption.
Performance and durability
Cloud storage needs to adhere to specific SLAs around performance and durability. SLAs are the bedrock of cloud computing, with the public cloud vendors promising that customers will receive a certain level of service when paying for the consumption of that service. Those SLAs are a double-edged sword though, and a customer can easily get burned if they don’t read the fine print. Things that were traditionally handled by the storage team on-premises, such as replication and backup of data, are not necessarily included in cloud storage services. Caveat emptor, indeed!
Consumption based model
One of the great things about the public cloud is the pay-as-you-go model for services. That extends to the consumption of storage. Here again, it is important to pay attention to each service and fully understand the way in which the service is billed. For instance, different tiers of the same storage service may have a slightly different way of charging for consumption, and that can come as a big surprise when the monthly bill rolls around.
Almost limitless scalability
Cloud hosters make money when services are being consumed, so it is in their best interest to remove any technical limitations that stand in the way of consumption. This creates the possibility for truly staggering scales of deployment. There are still limits, however, so it is key to understand what those limits are and when you might encounter them.
Shared infrastructure model
It shouldn’t come as a surprise that services in the public cloud are multi-tenant in nature. The only way for cloud vendors to achieve economies of scale is to maintain a high-level of utilization across their hardware stack. Making all solutions multi-tenant enables public cloud vendors to keep that utilization high, but it also means that your applications and storage are sharing a common platform with other customers. The level of sharing is dependent on the service, with some services like S3 sharing at the software platform layer, while others, like VPCs, sharing at the physical and logical layers.
Closer examination

With the core constructs discussed above in mind, let’s take a closer look at the services offered by the two biggest cloud players out there, AWS and Azure.
Amazon Web Services
AWS has three separate storage services for consumption. Simple Storage Service (S3) is the OG on the block[1], providing nearly limitless object based storage for clients. Elastic Block Store (EBS) is a block-based storage service that provides storage to EC2 instances. Finally, there is the Elastic File System (EFS) which provides NFS file system mounts to Linux-based EC2 instances. That covers the main storage types outlined earlier. Let’s take a look at some of the features and limitation of each of these services.
Simple Storage Service
S3 is a an object-based storage service that is hosted in the AWS cloud. It is great for cloud-native or newer applications that are comfortable using an object-based storage type to store and retrieve data. Traditional applications are not going to know what to do with S3, although there are some shims that will abstract S3 as an NFS or SMB file system.
S3 provides programmatic access for the creation of S3 buckets and objects in the buckets. The durability of S3 data is extremely high, 99.999999999% according to their SLA. The uptime for S3 is only 99.99%, which is equal to roughly 53 minutes of downtime a year. That is likely adequate for many services, but it is recommended to replicate critical data to an S3 bucket in another region. Pricing is based on the amount and type of storage consumed, and the number of operations performed on that storage. According to AWS, there is no limit on the number of objects you can store in S3, but the maximum size of an individual object is 5TB. Performance is dictated by prefixes in a bucket, which is a folder-like object storage container. Each prefix can support 5,500 GET requests per second, and 3,500 of other types of requests per second.
Elastic Block Store
EBS is a block-based storage medium that can be presented to EC2 instances. An individual EBS volume cannot be attached to more than one EC2 instance, so it is not possible to use EBS as a shared storage system.
EBS provides programmatic access for the creation of volumes and attachment of those volumes to instances. The durability of EBS is not exactly quoted, but it works out to about 99.9%, so one can assume that roughly one out of 1000 volumes will fail each year. With proper snapshot management, this shouldn’t be a significant issue. Availability is sitting at 99.999%, and is dependent on the availability zone used to deploy the EBS volume. Pricing for EBS is based on storage consumption, with an additional fee if provisioned IOPS are desired. The maximum size for a volume is 16TB, and each volume can handle a maximum of 32K IOPS and 500MB/s of data transfer. Multiple EBS volumes can be attached to a single instance, creating a RAID set that stripes data for increased performance. In that case the limitation is the EC2 instance itself, maxing out at 80K IOPS and 1,750MB/s of data transfer.
Elastic File System
AWS soon realized that there are a lot of applications that are dependent on NFS for file storage. Since people might not want to rewrite their application to use S3, AWS instead decided to introduce EFS, which is basically NFS as a service. EFS can be presented to multiple instances running a Linux OS. Instances running Windows are not allowed to join the party.
EFS provides programmatic access for the creation of the file system, exposing mounts to instances. The durability and availability of EFS are not stated in the official AWS documentation. The service does straddle AZs in a region, so it’s safe to say that the availability SLAs should be the same as that of the region itself. Once again, it would be prudent to replicate critical data outside of the region. Pricing for EFS is based on the amount of storage consumed, with a separate charge for provisioned throughput. There is allegedly no limit on the size of an individual EFS file system, and in fact the performance of the system should increase as the file system grows. This is because the file system is distributed across multiple storage nodes. As the file system grows, it spans more nodes, and so the aggregate throughput also increases. The average throughput is about 50MB/s per TB of storage with bursting up to 100MB/s.
Azure
Azure takes a different approach when it comes to their storage offerings. All the various offerings are housed within a construct called a storage account. There can be multiple storage accounts per subscription, and each storage account does not have to use all of the offerings. There’s probably some underlying architecture in Azure that created a requirement for these services to be bundled in storage accounts instead of being offered separately.
Azure storage accounts
The Azure API provides programmatic access for the creation and management of storage accounts in each region of Azure. The storage account itself has a 99.99% SLA on availability. Storage accounts can be locally redundant, zone redundant, or geo redundant. Local redundancy creates three copies of each piece of data within an availability zone. Zone redundancy creates copies across availability zones in a region. And geo redundancy creates three additional copies in a partner region. Data durability for each object in the storage account is 99.999999999%. The storage account itself has no cost associated with it. Each storage account can hold an aggregate of 5PB of data. It can also handle a maximum of 50K requests per second, and a maximum bandwidth of 50Gbps.
Storage accounts can house blob, file, table, and queue storage services. Blob and file are the two services most comparable to AWS, so table and queue will not be examined.
Blob
Blob storage is an object-based storage service made up of containers and objects. Containers are similar to prefixes in the world of S3. There are different types of blobs: page, block, and append. In simplest terms, page blobs are used to house the VHD files that back Azure VMs. Block and append are used for everything else.
Blob storage provides programmatic access for the creation of containers and objects within the storage account. Blob storage inherits the availability and durability of the storage account it resides in. Blob storage is priced by storage consumption, data transfer, and various operations. The maximum size for an individual object is 4.7TB for block and 8TB for page. The maximum throughput for a single blob is 60MB/s.
Managed Disks
Technically, the VHDs that back Azure VMs reside as page blobs on Azure Blob storage. Managed Disks create storage accounts that are both managed by Microsoft and offer higher levels of performance. Managed Disks for Azure VMs was a response to customer demands to simplify the management of disks for virtual machines. Rather than manually creating storage accounts and trying to balance the performance of VHD page blobs across multiple VMs, Microsoft opted to introduce Managed Disks, which take care of the creation and maintenance of storage accounts for VHDs and also offer standardized performance levels.
Just like blob storage, the programmatic access, availability, and durability are the same for Managed Disks. The maximum size disk is 4TB, and there is no hard limit on the number of managed disks per account. The premium level of Managed Disks offers a maximum of 7,500 IOPS and 250MB/s of throughput. Multiple premium disks can be attached to a single VM to increase throughput and capacity. A single virtual machine tops out at 80k IOPS and 2K MB/s of throughput, so the bottleneck – if you can call it that – is the virtual machine itself. Pricing for Managed Disks is capacity based.
File
Azure File service is an SMB file service that can be presented to Azure VMs, or really anything capable of connecting to an SMB path. Both Windows and Linux operating systems are supported, though most Linux admins would likely turn their nose up at using an SMB/CIFS file system instead of NFS.
File storage provides programmatic access for the creation of file shares and files. File storage inherits the availability and durability of the storage account it resides in. File storage is priced by storage consumption and various operations. The maximum size of an individual file share is 5TB, and it maxes out at 1000 IOPS. The maximum throughput for a single file share is 60MB/s.
Challenges around these options

With all these options available, it can be hard to determine which service most closely aligns with a particular application’s needs. Likewise, there are some things to keep in mind when it comes to support. Here’s a handy table for reference.
| Service | Protocol | Availability | Durability | Max Size | Max Throughput |
| S3 | Object | 99.99% | 99.999999999% | 5TB object | 5.5K GET, 3.5K Other |
| EBS | Block | 99.999% | 99.99% | 16TB | 32K IOPS, 500MB/s |
| EFS | NFS | Unknown | Unknown | 48TB | 100MB/s per TB allocated |
| Blob | Object | 99.99% | 99.999999999% | 4.75TB (block) 8TB (page) | 60MB/s |
| Managed Disk | Block | 99.99% | 99.999999999% | 4TB | 7.5K IOPS, 250MB/s |
| FIle | SMB | 99.99% | 99.999999999% | 5TB | 1000 IOPS, 60MB/s |
Of course this is for only two of the public cloud vendors. One can imagine how this table would expand if all cloud storage options from the major vendors were included.
There should probably be a footnote for the values in almost every column, due to the number of caveats regarding each service[2]. For instance, EFS does not support Windows clients. Azure File does not support the NFS protocol. Azure Blob statistics are per storage account, and S3 does not have a concept of storage accounts. The maximum bandwidth for a service is actually a combination of the service itself and the service consuming it, like the network bandwidth limitations on an EC2 instance that is using EFS. And that is simply from trying to compare two public clouds. The mind reels at the caveats and footnotes required to compare storage solutions across Azure, AWS, GCP, Alibaba, Digital Ocean, and yes, even Oracle Cloud.
An Appeal for Consistency
In the same way that we have standards like SCSI and FC, it would be great for the cloud providers to land on a similar standard for storage interfaces. NFS and SMB work at the application protocol level, but what about the control plane where storage is allocated, managed, and monitored? It would be amazing to have a defined minimum standard that each cloud vendor adheres to, in order to make management and consumption of multiple clouds simpler. Each cloud service is welcome to bring their own special sauce to the party as an extension to the basic standard. But there should be some commonality that makes the life of a cloud storage admin slightly simpler. The on-premises world faces similar issues. Zoning Fiber Channel fabrics and provisioning LUNs are standard constructs, but the management tools for each vendor are different and not compatible. The cloud is a chance to begin anew, rather than building walled gardens of functionality.
It could even be argued that there is an overall business advantage to settling on a defined standard. By lowering the barriers to entry, potential customers are more likely to adopt new technologies and abandon their existing environments in favor of easy to manage clouds.
Common standard for management
If there were a wishlist for a common standard for management it would include multi-cloud support. The same management tools that work with AWS would also work with Azure. Likewise, each cloud would agree on a standard reference API that would be adopted across all clouds to simplify the programming and management of multiple clouds. The billing model and cost structure would be the same, although the prices would naturally differ. Performance would also be measured in a consistent manner, to aid in comparison of offerings, and a standard minimum level of performance would be available at set tiers. Lastly, the services would be able to exchange metadata and synchronize data across clouds.
Clearly, this is a wishlist, and with the number of people already using these public cloud services, it is a tall order to ask the vendors to restructure their management, performance, and cost to create some type of consistency. Additionally, as the public cloud becomes more commoditized, the vendors are going to want to add as many bells and whistles as possible to their offering to differentiate from the rest of the pack. In fact, the only real hope for such a consistent and common standard lies with net new offerings from third party vendors. NetApp is an example of a vendor that is trying to do exactly that.
NetApp ONTAP and Cloud Volumes
NetApp recently announced the availability of Cloud Volumes Service for Azure, AWS, and GCP. A Cloud Volume is a NFS file system created in one of these three public clouds, and made available as a mount point for systems within that public cloud. The provisioning of cloud volumes can be done through NetApp’s Cloud Central website or in the case of Azure or GCP, through the cloud provider’s native API. Previously, NetApp had a solution called Cloud Volumes ONTAP, which leveraged each public cloud provider’s compute and storage solution to create a virtual NetApp storage array. The Cloud Volumes Service eschews that in favor of running on some undisclosed, bare-metal, multi-tenant solution that is tightly integrated with the networking of each public cloud. NetApp controls the hardware and software stack, giving it a performance boost that was not possible when using the virtual array approach of Cloud Volumes ONTAP.
How does the Cloud Volumes Service stack up against the wishlist? Well, for starters, using the Cloud Central web portal or API creates a common control plane for all of these public cloud deployments. The Cloud Volumes Service still plugs into the ONTAP features, which enables a single interface for monitoring performance and tracking usage. Since NetApp is controlling the hardware and software stack, the performance across public clouds should meet a standard minimum, with any differences likely being the fault of the public cloud service itself. NetApp doesn’t control the networking performance of AWS, GCP, or Azure, nor does it control the throughput maximums of the compute resources consuming Cloud Volumes. Pricing for the solution has not been made publicly available, but one would hope for a consistent pricing scheme across all three providers. Finally, since NetApp is managing the data and the metadata for the solution, the challenge of syncing between public clouds should be greatly reduced, and possibly deduplicated. Ideally, that would reduce the network egress between the public clouds and help customers save a little money while still being able to replicate data across public clouds.
Cloud Volumes is still very much in preview, and it’s clear that the product is still trying to figure out how customers want to use it. With any luck, the folks at NetApp are keeping their minds and ears open to feedback and looking for ways that their solution can make cloud storage a little better for all of us.
Stephen Foskett contributed to this article.
[1] For purposes of cloud storage services, otherwise that honor goes to Ice-T.
[2] Editor’s Note: Thank you