A lot of vendors claim to have distributed storage. Certainly many of them will sell a solution marketed as distributed. The issue is that a lot of what is marketed as distributed relies on legacy implementation. These were made with the standard storage needs in mind. Capacity, reliability, and speed aren’t hard to find these days. You know what is really hard to do? True distributed storage. That’s where StorPool comes in.
StorPool isn’t just offering a monolithic storage platform that can be extended. And they’re not providing a half baked beta products that works in a lab but hasn’t been tested. StorPool was started in 2011, and for the last four years has had systems in production. They’ve scaled up to petabyte storage, and overall have a legacy of working in the real world.
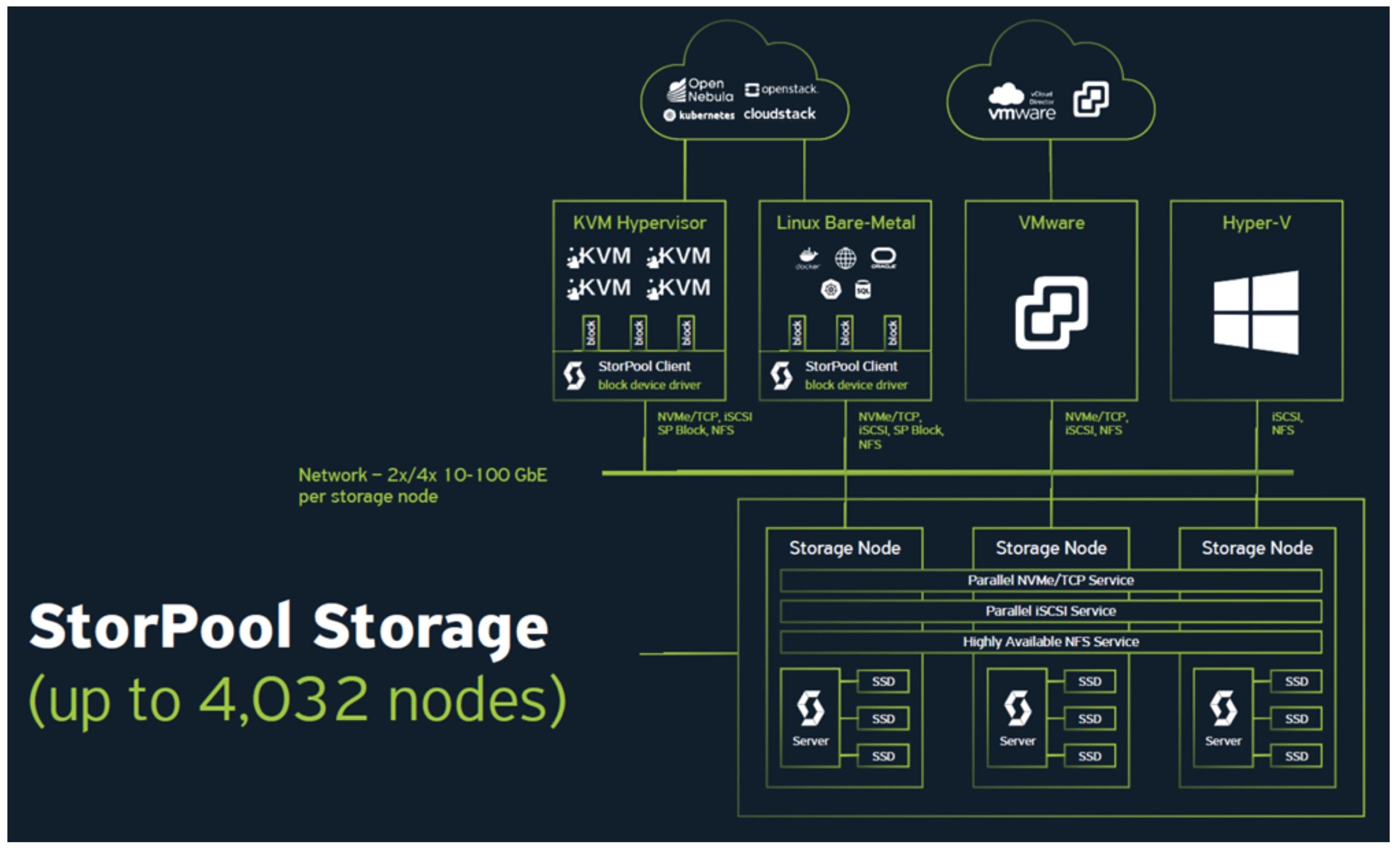
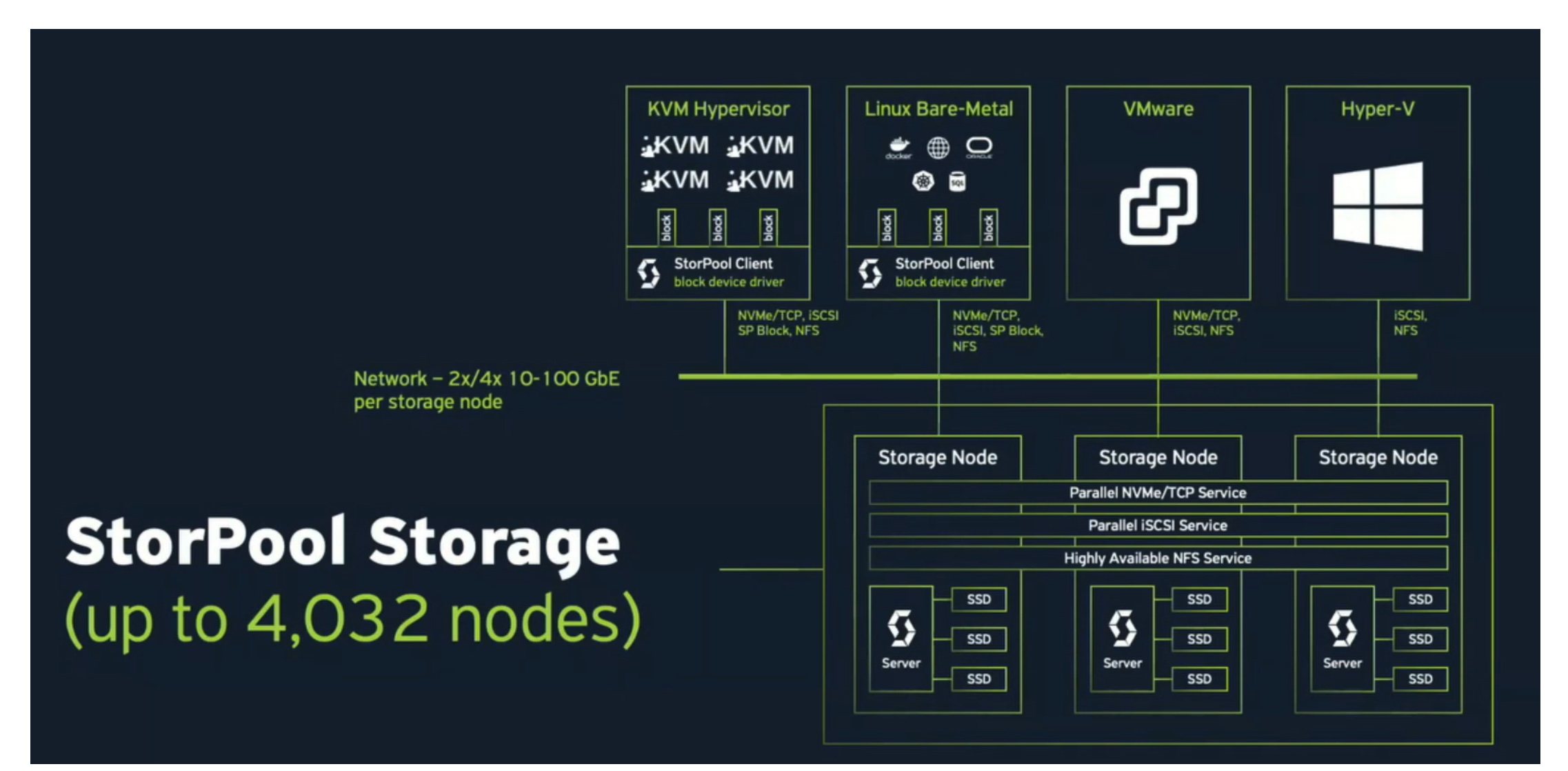
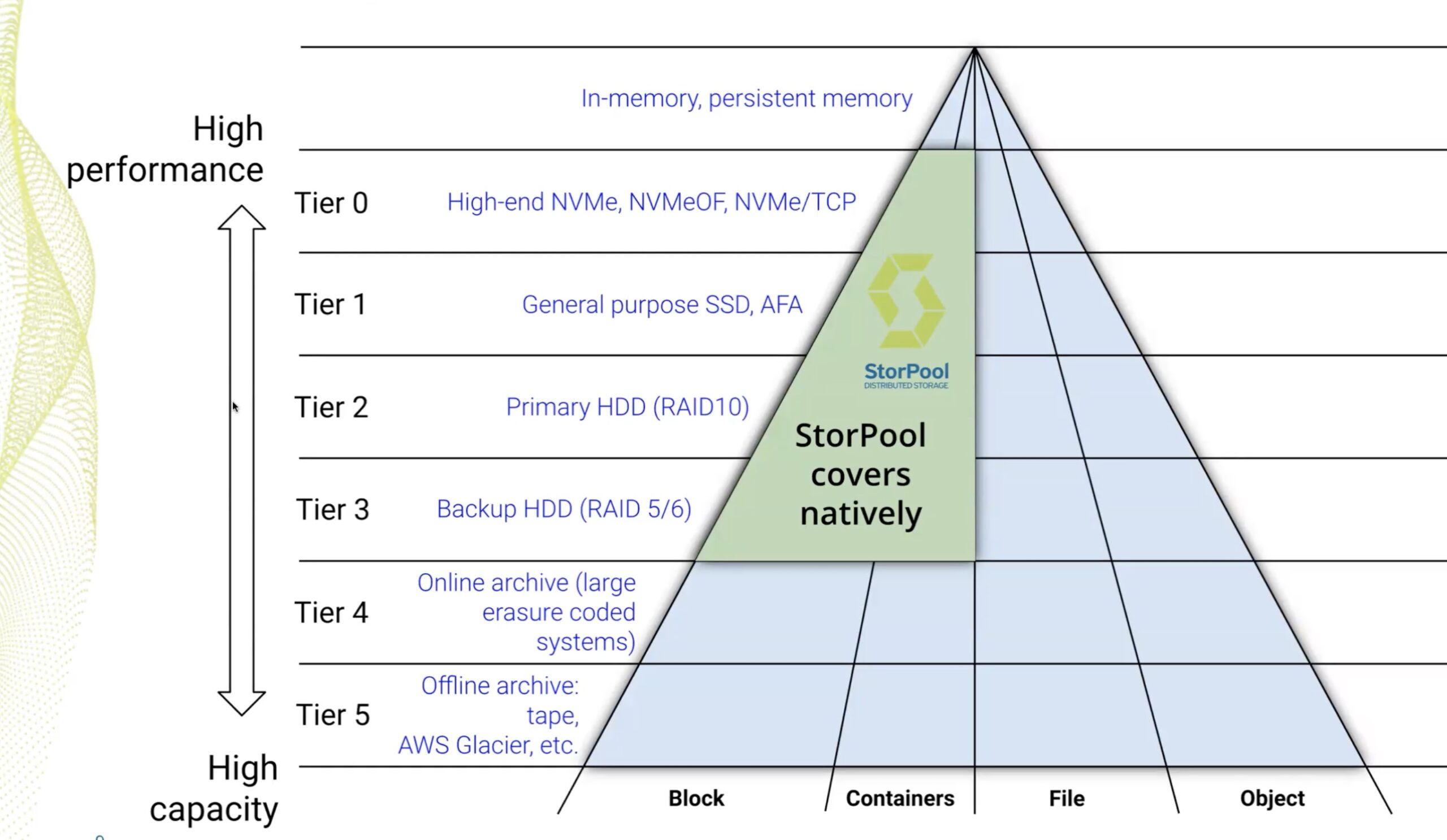
StorPool allows you to pool capacity across servers into one logical pool. This runs across the spectrum of Linux systems, providing block level storage. Their main goal is to compete with the big players SAN players (looking at you Isilon). Essentially, they’re aggregating all local capacity and performance into on logical pool. From their, using either Ethernet or an Infiniband backend and their custom drivers, you can get true distributed storage across servers. This is accomplished without any kind of metadata servers, or overall controllers inserted into the mix.

StorPool really touts their custom solution, for good reason. They’ve engineered the networking, formatting, core management, drivers from the ground up to get this to work. Their solution seems to scale pretty well. Because they don’t need a management layer for their distribution, they can get their solution off the ground with just three servers, generally they’re seeing those kind of deployments offering 5-10TB usable. These scale up to over 100TB per cluster, and they’ve seen petabyte scale with larger distributions. I pushed them about how large they could go, and while they haven’t seen deployments above 10PB, there’s no technical reason it couldn’t scale above that. In fact, their next release will have change to code to specifically clean up how their system address multi-petabyte clusters. It may be an academic argument however, since most companies may not want to aggregate this much storage. I didn’t get a firm answer as to how many servers they could support in one pool, but they didn’t seem to have hit a hard technical limit, which is encouraging.
In terms of performance, they’re claiming some pretty lofty numbers. They’re claiming to deliver 100,000 IOPS and 1GB per second per storage node, using fairly minimal memory and compute. They can support SATA, SAS, and NVMe.
To me, what was impressive was the company’s commitment to making sure their customers could get this solution running. This isn’t a simple software solution where users download something, click through some config prompts, and then when something goes wrong they’re on the phone with support for hours. No, StorPool builds in comprehensive support and setup into their pricing model, which is a big commitment, but in my eyes is a pretty great value add. Since they’re putting themselves on the line for installation, tuning and support, it also might lessen the personnel needs for overall maintenance. To be honest, I was a little skeptical of this point, I think I would still rather overstaff than rely on a service contract for one part of my datacenter, but your mileage may vary.
StorPool thinks they’ve done the hard work to get distributed storage working in the enterprise. Just about everyone claims to have some sort of scale out strategy, but StorPool actually achieves this. Getting familiar with their solution, I kept waiting for the “but” moment. When they’d casually mention how you need a control nodes as the distribution expands, or some sort of dodgy emulation to get the whole thing to work. But from what I’ve seen, it’s the real deal. Right now StorPool lists an array of hosting and virtual private server companies for their clientele, which makes perfect sense for their product. We’ll see if they can extend further into public and private cloud space going forward.
Update: Article updated to include comment on the upcoming StorPool software release, as well as to correct the minimum number of servers needed.