Gestalt IT recently held a showcase with Intel on the performance and the total cost of ownership (TCO) of running AI workloads in the cloud. I was one of four delegates that got the opportunity to tune in live and ask questions of the presenters.
One thing that made this showcase special was that rather than simply telling us how great they were themselves, Intel brought in partners Wipro and Accenture to present the results of their independent testing and benchmarking. In this post I’m going to dive into what we learned from the Accenture presentation on AI TCO, as well as a bit of context around why this is important and timely.
Let’s dive in!
Cloud Meets AI
Everywhere you turn, it seems, someone is talking about “the cloud” or about artificial intelligence (AI), machine learning (ML), and artificial neural networks (ANN), etc. It’s really all about “digital transformation,” which of course is actually all about providing digital experiences to customers and continuing to blur the physical/digital boundary in products and services.
In the pursuit of these highly desirable digital experiences, more and more enterprises are leveraging AI in their applications, and many of them are doing it in “the cloud.” But at what cost? The easiest and most common way to consume compute resources in the cloud is with pre-packaged virtual machines that include a set “recipe” of CPU, RAM, and network resources. That can severely limit our ability to optimize hardware configurations for our specific use-cases. And while the cloud’s pay-as-you-go model can be very attractive, it can also lead to runaway costs when demand increases. So, how can we ensure the highest performance and the lowest total cost of ownership (TCO) when running AI workloads in the cloud?
Intel Optimizations
Intel provides software optimizations that directly address these questions around both price and performance of AI workloads in a public cloud. I’ve written fairly extensively in the past about Intel’s focus on improving and supporting AI development through software tools, including Analytics Zoo, AI Builders, and OpenVINOTM. Today, we’ll build on that with a peek at two optimization specific “tools” from Intel. The first is the Intel Extension for Scikit-learn and the second is the Intel® oneAPI Data Analytics Library (oneDAL) C++ API.
First, a refresher on Scikit-learn, from Wikipedia: “Scikit-learn (formerly scikits.learn and also known as sklearn) is a free software machine learning library for the Python programming language. It features various classification, regression and clustering algorithms including support [for] vector machines, random forests, gradient boosting, k-means and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy.” If you’re building AI applications, you likely already knew that.
What you may not have known is that the Intel Extension for Scikit-learn is a software library for accelerating AI, ML, and analytics workloads on Intel CPUs and GPUs. It’s written to provide the best possible performance on Intel Architectures with the Intel oneAPI Math Kernel Library (oneMKL). What’s more is that it requires a minimal impact to existing code; just install the latest patch using PyPI or conda-forge install! Further taking advantage of the OneDAL performance improvement opportunity is a bit more involved as you must add the library and include it in the code. However, as you’ll see, the extra effort in refactoring can be well worth it.
You can find all of these AI developer tools and resources on the Intel website, along with tons of AI workshops and additional learning resources.
Price and Performance Improvements
I recently had the pleasure of hearing Accenture’s Ramtin Davanlou in a Gestalt IT Showcase with Intel present on Reduce Your AI TCO With Hardware and Software Optimization. The presentation reflects on the results of benchmark testing that “analyzed the performance and cost implications of choosing Intel® Xeon® versus Graviton VMs for several AI/ML algorithms including XGBoost, logistic regression, k-means, and random forest.” and also looked into “how the Intel® software optimization (Intel® Extension for Scikit-learn, also known as oneDAL and daal4py) could boost the performance of its CPUs.”
The results are striking, and I’ll let them speak for themselves with a couple charts summarizing the performance improvements:
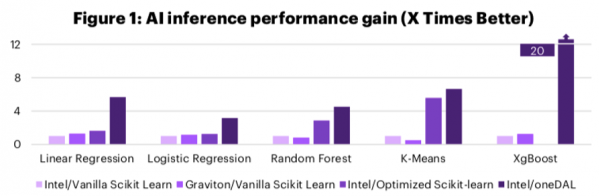
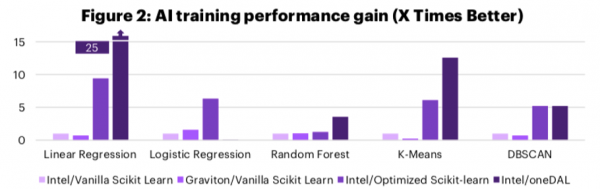
As you can clearly see, the Intel software optimizations have a very consistent and outsized impact on the performance of AI workloads in the cloud. In this case we’re looking at AWS EC2 instances. The baseline (1X) performance is set in the first test (Intel VM with Vanilla Scikit). While the Graviton VM can sometimes best that mark, it never surpasses the performance-optimized Intel VM.
But what about TCO? After all, the Graviton VMs being tested here are on average 40% cheaper than their comparable Intel VMs on AWS. Can software optimizations close that gap? Let’s take a look:
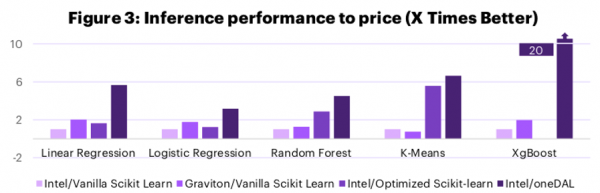
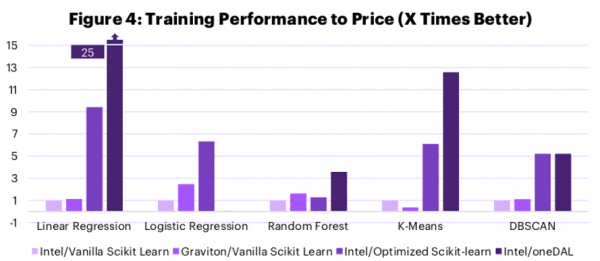
Yes, you’re reading that right. The performance boost provided by Intel’s free software optimizations is enough to drive significant performance to price advantages, which should translate directly to a lower TCO.
The Bottom Line
In the pursuit of ever better digital experiences for their customers, modern companies continue to place big bets on both cloud and AI. But as all IT professionals know, there are no blank checks in business. Luckily, it turns out that the performance improvements provided by Intel’s oneDAL and other AI software tools are so large that they can drastically reduce overall TCO. You can learn more about how Intel oneDAL reduces AI TCO by watching their Tech Field Day video showcase. You can also visit Intel.com or consult your Intel sales representative for more information



