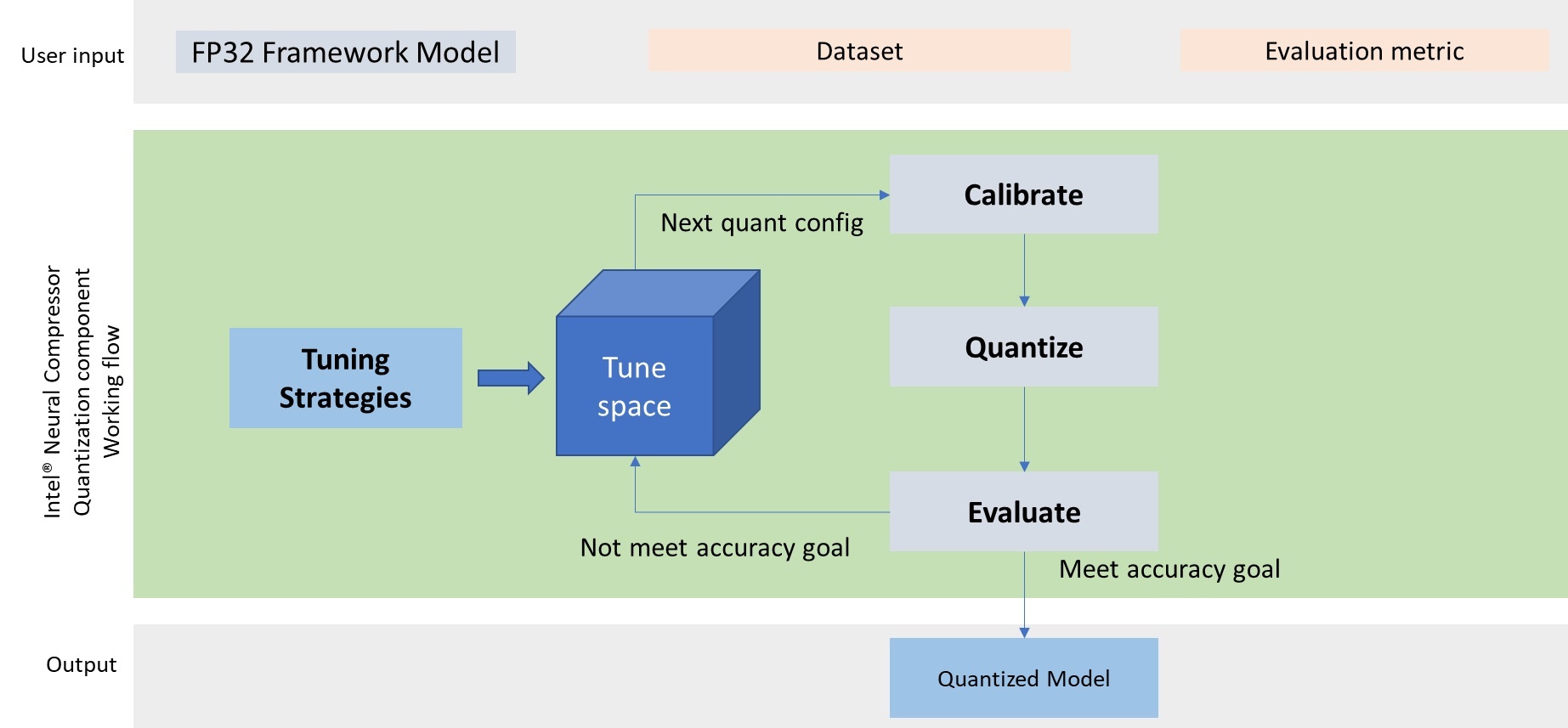
Intel® Neural Compressor (formerly known as Intel® Low Precision Optimization Tool) is an open-source Python library running on Intel CPUs and GPUs that provides popular neural network compression technologies, such as quantization, pruning, and knowledge distillation. It provides a single, unified interface to multiple deep learning frameworks, including TensorFlow, MXNet, PyTorch, and ONNX Runtime.
Intel® Neural Compressor supports automated, accuracy-driven tuning strategies to help data scientists quickly find the best quantized model for their particular data model. It also implements a variety of weight pruning algorithms to generate pruned models with specific sparsity goals and supports knowledge distillation to move knowledge from teacher models to the student models.
Implementing these techniques manually can be tedious and complex, requiring detailed knowledge of the underlying framework as well as how best to construct and tune the compression techniques. Neural Compressor automates much of the tedium, providing a quick and easy way to obtain optimal results in the framework and workflow you prefer.
Why Use Intel® Neural Compressor?
Deep learning training and inference is resource intensive. It requires a lot of data, and high-precision data consumes much more space than lower-precision data.
This places a lot of pressure on memory sizing, and fast memory is expensive, but the greater challenge is the time it takes to compute on large, high-precision models. Even with infinite money, you can’t buy more time, and you can only buy the fastest memory and CPUs that actually exist. Learning and inferencing is often iterative, particularly during model development, so the time taken accumulates with each train and test cycle. And while the computation is running, there is little for data scientists to do but wait.
But we can use resources more efficiently, particularly if total precision isn’t actually required. There are multiple benefits if you can produce good results with a smaller, lower-precision dataset. A smaller dataset fits in less memory, lowering costs. It’s faster to move the data across the memory bus, speeding up cycle times. And the model is faster to compute on because of how it fits into memory.
If you’re renting compute instances by the hour in the public cloud, these savings can add up substantially. But even if you’re running models on static infrastructure, faster throughput means faster results, and more opportunities to try more things. Or simply getting the answer you need quicker, so you can move on to what you really want to do instead of sitting around waiting for a model to finish training. These benefits are qualitatively better, not merely economic gains; it’s just a lot more enjoyable to work on problems without having to wait around for slow infrastructure all the time.
Getting good answers quickly is what we’re trying to do, after all.
Quantization With Neural Compressor
The 32 bits of precision of a float32 datatype requires four times as much space as 8-bit precision of the int8 datatype. You can convert a high-precision float32 number to an int8 number using a process called quantization which takes samples of the original, smooth number to give you a rough approximation.
This is essentially how MP3s work to give you acceptable quality audio compared to the full fidelity of a live performance. It’s good enough for listening to while you’re going for a run, and much more convenient than carrying a band and all their equipment on your back.
CERN, the European Organization for Nuclear Research, has used Neural Compressor to improve the performance of a 3D Generative Adversarial Network (GAN) used for measuring the energy of particles produced in simulated electromagnetic calorimeters. Quantization with Neural Compressor provided around 1.8x faster processing with 8 streams and 56 cores.
Alibaba, meanwhile, achieved approximately 3x performance improvement by quantizing to int8 with Neural Compressor for its PAI Natural Language Processing (NLP) Transformer model which uses the PyTorch framework. The quantization resulted in only 0.4% accuracy loss, which was deemed acceptable for the workload goals.
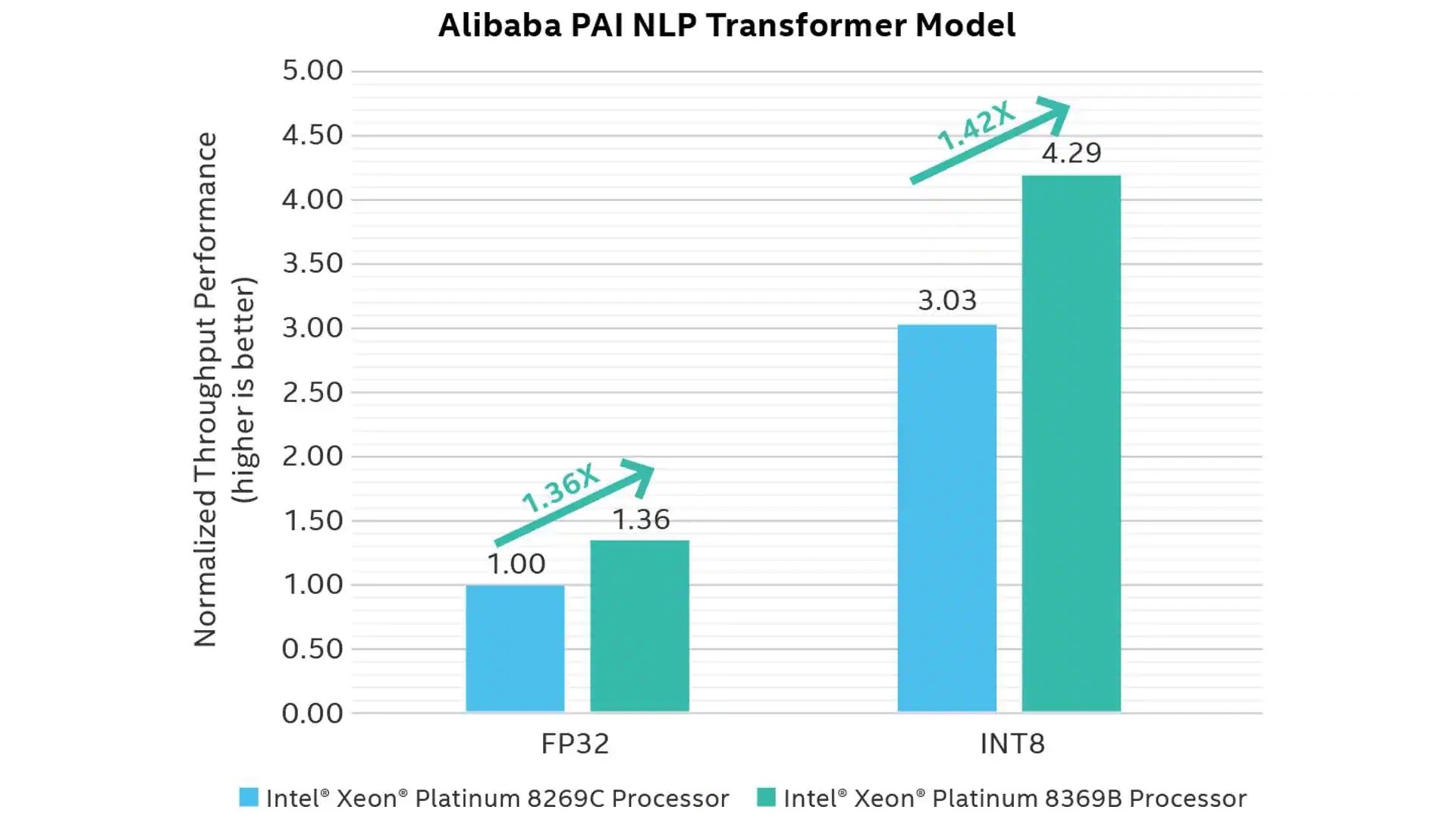
Figure 1.2: Generational speedups for FP32 and INT8 data types
Pruning With Intel® Neural Compressor
Pruning carefully removes non-critical information from a model to make it smaller. This is a different approach from the quantization method, but the goal is the same: get good enough results from a smaller model so that you can get those good results faster and with fewer resources.
Intel® Neural Compressor supports a variety of pruning techniques including basic magnitude, gradient sensitivity, and pattern lock.
Pruning is traditionally quite complex, requiring manually tuning many iterations and a lot of expertise. Neural Compressor automates a selection of techniques and can combine them with quantization techniques
Pruning provides many of the same benefits as quantization, and because it is a different technique, the two approaches can be combined. Neural Compressor supports pruning followed by post-training quantization as well as pruning during quantization-aware training methods, providing extra efficiency.
Using the Power of Open Source Software
Intel® Neural Compressor is open source, available at https://github.com/intel/neural-compressor so you can easily add the library to your toolbox. And if you’re just getting into machine learning and learning how neural networks work, you can dig into the code to see how quantization and pruning actually works. Or just see working examples of what NumPy flatten() and reshape() are used for.
Once you have a model (an example mobilenet model) and some evaluation parameters (see an example here), using the library requires just a few lines of Python, as you can see below:

Learn more about how to use Neural Compressor in your projects with the tutorials and detailed documentation included with the code.
Conclusion
While the realm of deep learning and neural networks can be extremely complex, the benefits of Intel® Neural Compressor are based on the same principles we’re already very familiar with in other parts of the technology stack. Lossy compression is an everyday staple in the music we listen to, the JPEG photographs we take with our cameras, and the streaming movies we watch. Using the same techniques to speed up deep learning processing is a natural extension of what we already do in many other places.
If we consider the reverse: taking twice as long to get a tiny improvement in precision that no customer will ever notice, not using these techniques seems wasteful in comparison.
Which is what makes Intel® Neural Compressor so compelling: why wouldn’t you want use it?
And beyond the pure performance and resource efficiency gains, there is a wealth of opportunity here for those new to deep learning who want to explore how these techniques work, both in theory and in practice. As a freely available piece of software that you can inspect and learn from, there’s little reason not to at least give Neural Compressor a try.
The power of modern frameworks and the ease-of-use provided by modern tools like Neural Compressor puts these advanced techniques within reach of a broad range of software developers and data scientists. When combined with on-demand cloud computing infrastructure, it’s easy to try it out for yourself to see if the claims are true. You can prove the results for yourself without a major investment in time and infrastructure just to test out vendor claims.
And if it performs as well as other customers have seen, customers like CERN, Alibaba, and Tencent, why wouldn’t you use it too?



