For decades we have seen incredible innovations in compute, storage, and networking. Virtualization, public cloud, and more recent adoption of cloud-native technologies like Kubernetes have become the new landing spot for many modern applications. Multi-cloud deployments are becoming a standard pattern. It can be by design, or simply because many applications have deployment needs that tie them to different cloud providers. But all of these innovations still leave a consistent challenge for developers and operators alike: How do we protect our applications and data as the infrastructure patterns change?
Data Protection is Broken
Data protection technology works well, but the implementation is often broken in modern applications. There has been a lack of focus on just how complex and costly data protection can be, especially in multi-cloud and hybrid cloud implementations. Traditional approaches to data protection involved layering software on top of applications and file shares and then moving copies of data to another storage destination. Even in traditional datacenters this approach loses any efficiencies achieved by the primary storage solution since the orchestration and data movement is performed outside of where the data is stored.
Applications are becoming more distributed, disaggregated, and complex. There are clear application-related advantages gained from using microservices and distributed application design patterns. The complexity tradeoff comes along with designing how to protect and recover those applications. That complexity leads to increases in both operational and people costs.
Multi-cloud amplifies the complexity but is virtually unavoidable as companies take advantage of the best capabilities of each cloud. The result is that DevOps teams have to build data protection processes that fit each cloud provider.
Complexity Comes by Design
Modern applications are generally being built with multiple application services, data services, and distributed architectures that also connect to other applications. It is complex enough to protect each tier of the application, but is exponentially more difficult in complex multi-cloud environments.
Multi-cloud complexity comes from multiple sources, including the following:
- Authentication and Authorization – Identity and access management is vastly different between the major public and private cloud providers. This means that backing up and restoring the application requires unique identity and access to be a part of the process.
- Proprietary APIs and Services – There is no “one size fits all” API to each cloud, or services across the clouds. Compute, storage, and networking will behave and cost differently between different clouds.
- Cost Management – Each cloud has its own cost model, reserved capacity model, and also contract-related bulk purchasing and discount options for enterprise customers. This makes it very difficult to predict and manage the costs for primary applications and their data protection requirements.
- Consistent Change by the Provider – Public cloud platforms innovate at a breakneck pace which means having to keep up with rapidly changing applications and infrastructure in your data protection designs.
- Inconsistent Data and Storage Service Models – Each cloud has proprietary database services, key-value stores, object storage, block storage, each of which have different service tiers and pricing.
It’s easy to see how this adds complexity to your data protection strategy. Operationalizing that strategy usually leads to even more complexity in practice.
The Cost of Multi-Cloud Complexity
A good data protection strategy should include in-site and off-site. When a “site” is a public cloud provider, we have to account for storing and recovering data in different regions. This requires more compute, networking, and access management in that cloud.
Many teams are also looking at how to store data from Cloud A into Cloud B for resiliency but it’s unlikely that an application can be recovered in Cloud B without a great deal of work. Another hidden cost that comes in real dollars is data transfer charges across regions and between clouds. Primary, secondary, and long-term storage is also complex to estimate pricing for. It’s likely that a third-party solution will be needed due to the continuous complexity battle in a multi-cloud design.
Kubernetes Komplexity
Kubertnetes is quickly becoming the most popular multi-cloud platform. It has become a common underlay regardless of which cloud or on-premises provider is used. This is a huge win to reduce complexity for the applications but it also comes with its own tradeoffs.
Data management and protection in Kubernetes adds a whole new layer of complexity. While containerized applications may be stateless, the data that they read/write/modify is probably stateful and needs to be persistent and centrally managed.
The applications and processes traditionally used to protect IaaS and VM-based workloads won’t work for containerized workloads. That puts applications at increased risk and adds complexity for operations teams.
Data Protection is Actually Application Protection
We talk about data protection all the time but the data is really there to support applications: Business may run on data but that data is managed and used by applications. Businesses must align the application with the data, and build data protection to map to recovery objectives.
The RTO (Recovery Time Objective) and RPO (Recovery Point Objective) will be individual for each application. Data protection has to align operational processes with policies and requirements. For example, an organization must size the media or backup servers appropriately to stream and process the backup data. But, this can come at a cost to the production storage which must treat the protection application as an additional workload.
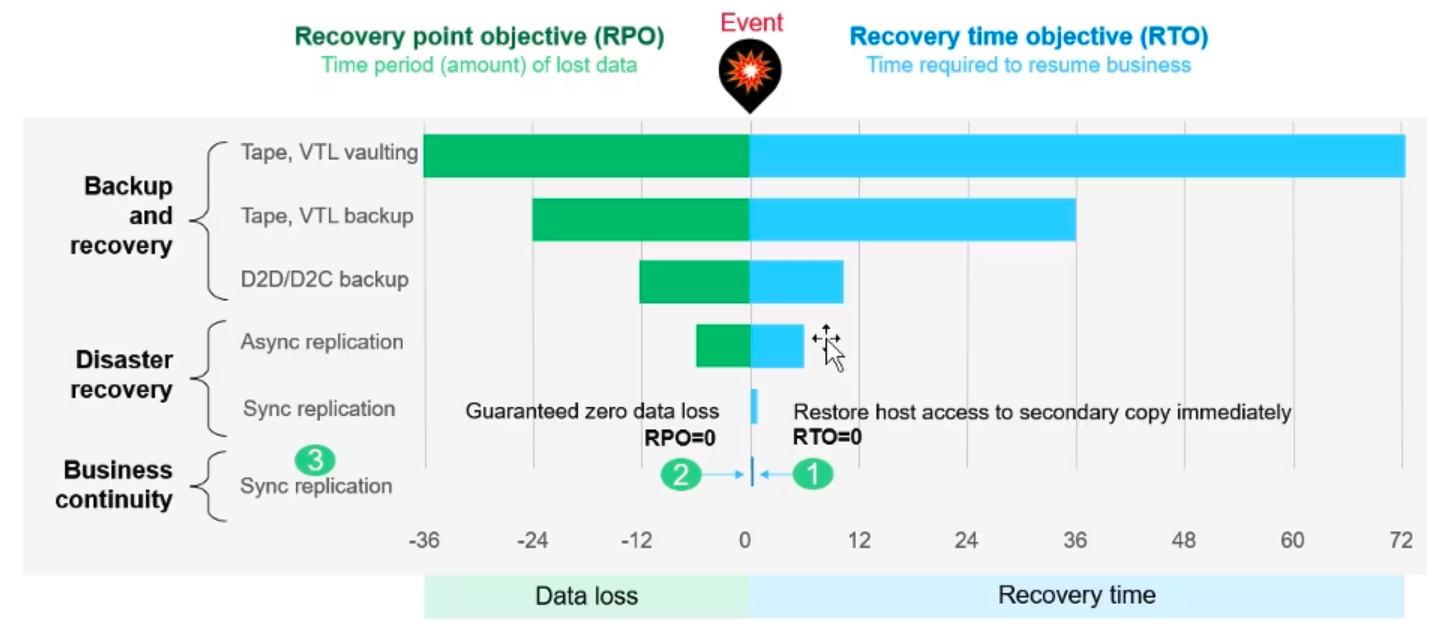
The following important questions about data protection must be considered for each application:
- What services and components make up the business application?
- What cloud dependencies does the application have?
- What data does the application need?
- Which applications are also sharing this data?
- What are the RTO and RPO of the application?
- What is needed to protect and restore this data based on the application recovery requirements?
- What is the plan for creating immutable storage options and backups in case of data issues (e.g. ransomware, viruses)?
This is the base from which we can define a data protection strategy, and it will influence how to build and manage a primary storage solution.
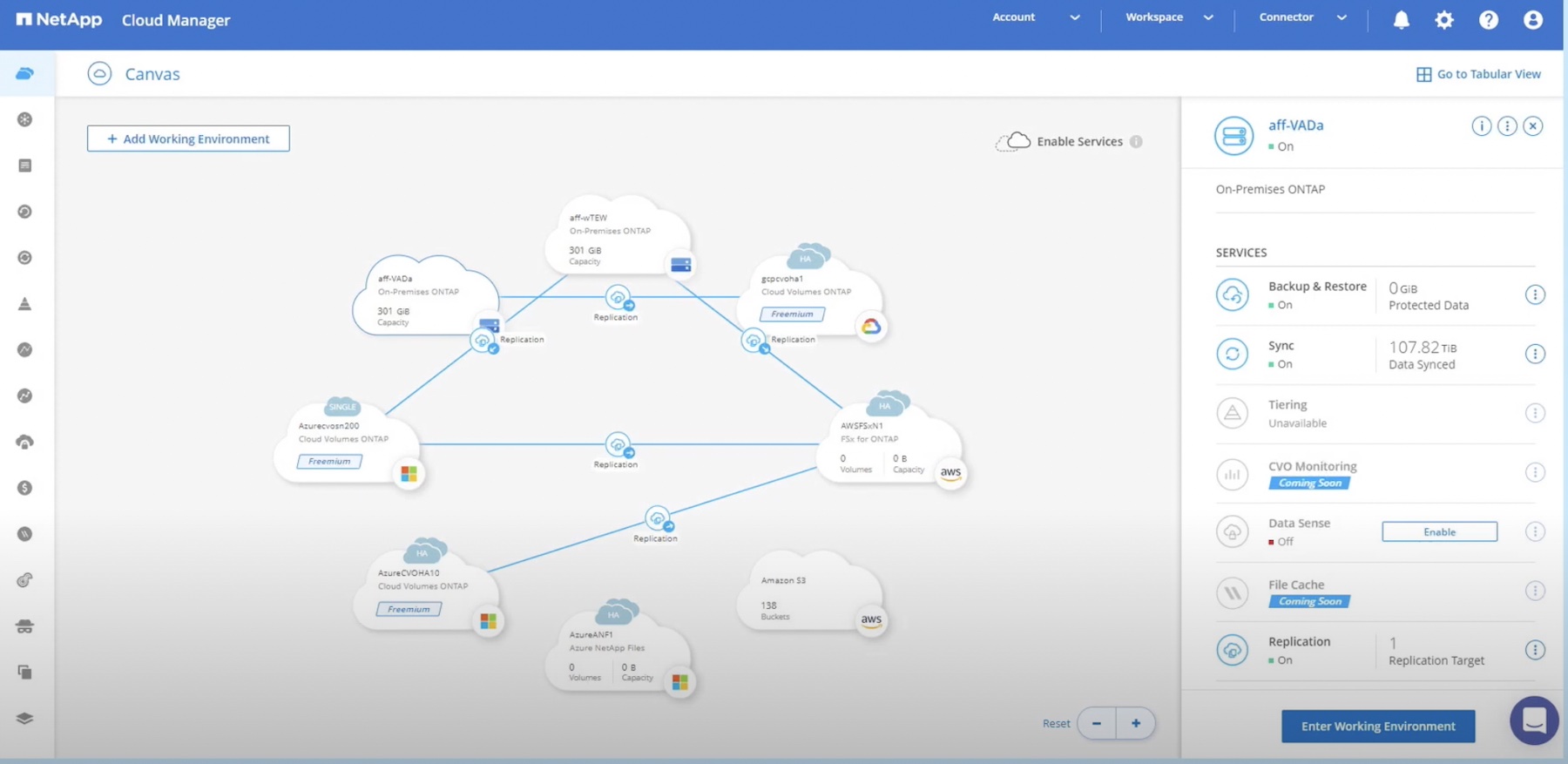
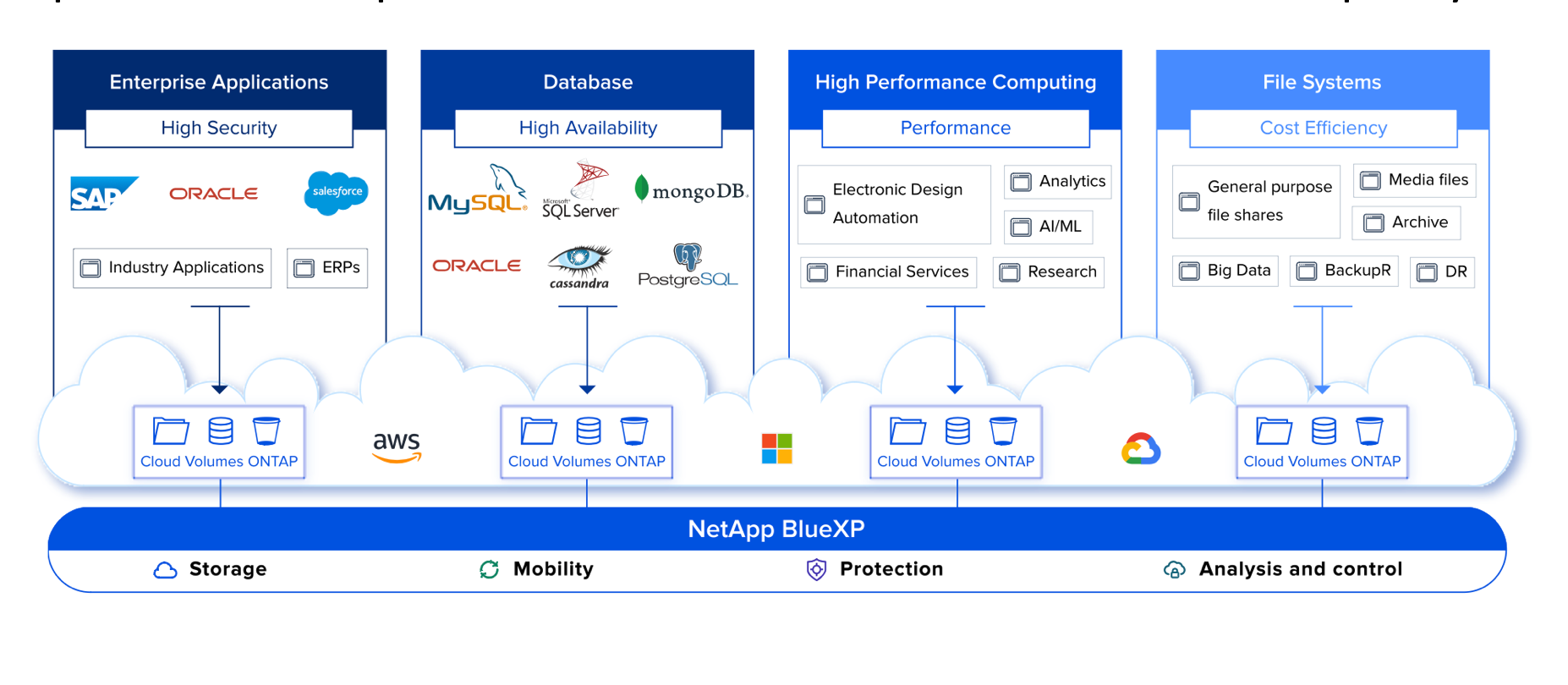
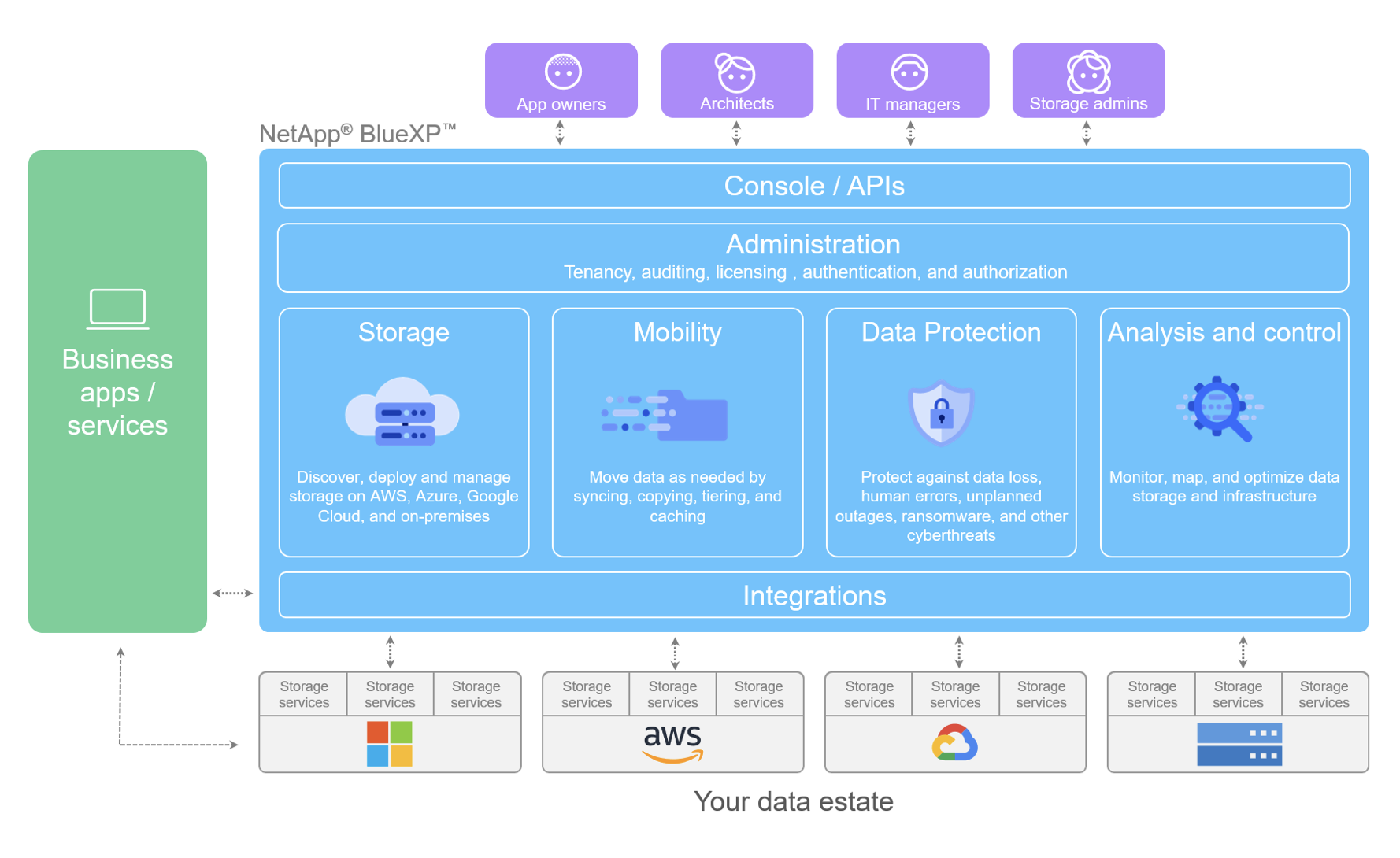
NetApp approaches the problem differently, since their storage is designed to efficiently create and quickly move data copies. When it comes to data protection NetApp ONTAP can effectively eliminate backup windows. Rather than using file-based streaming, ONTAP data protection creates space efficient copies of data using snapshot technology. ONTAP then moves the snapshot copies to secondary storage or object storage, using block-based data replication, in 4k byte chunks. The advantage is that only the changed bits move, and not the complete file. Another benefit to this approach is that all of the storage efficiencies of data deduplication and compression are retained from source to destination. The result is far less data movement, which accelerates protection and minimizes load on the production storage. Recovery time as well as data loss can be dramatically reduced as more frequent copies can be made and stored. All of this can be orchestrated out of the data path by BlueXP.
Additionally, placing the responsibility for protecting data on the storage means that there is less room for error and complexity. The storage system is aware of the location and distribution of data copies, resulting in one less point of management. As the application environment becomes more dispersed, deploying protection with the data is a more efficient and secure approach compared to more complicated streaming solutions.
Conclusion
There will be more complexity and costs as companies build data protection for multi-cloud environments. It’s a matter of managing the tradeoffs using data storage and management platforms that can provide consistency across multiple clouds.
The more consistency we can create, the easier it will be to protect and recover the applications. Multi-cloud data protection is not simple, but it’s necessary. It’s got to be a goal as operators to find the ideal platforms and solutions to meet the needs of applications and create operational consistency wherever possible.