There hasn’t been a time to be more excited about life sciences and the value that genomics and drug discovery bring to our societies. We have reached a point where our ability to process staggering amounts of data in record times strongly accelerates research. In fact, genomics data storage needs are skyrocketing: the data footprint is doubling every seven months. By 2025, it is projected that between 100 million to 2 billion humans will have their genomes sequenced, requiring from 2,000 PB to 40 exabytes of storage per year.
Genomics: A Workflow-based Approach
In life sciences, and particularly in genomics, data processing is highly sequential and follows a workflow-based approach, where data is analyzed, copied, accessed, and transformed multiple times, as seen in the high-level illustration below.
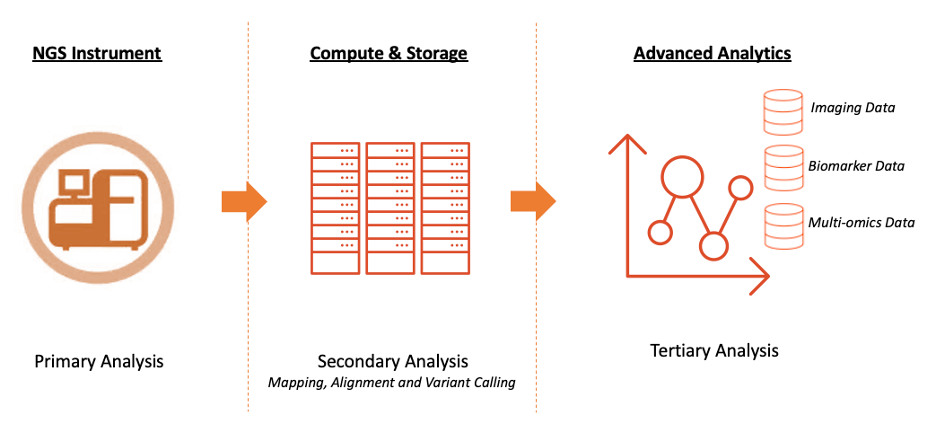
Processing raw data to make it accessible for further analysis requires several steps involving data transformation:
- Raw data is copied from the sequencing instruments to fast storage and subsequently archived on object storage
- Raw data is accessed for initial processing (demultiplexing) and transformed in processed files
- Checksums are executed against transformed data to validate consistency
- After checks are completed, data is accessible for secondary and tertiary analysis
Those steps involve copying data between various storage and reprocessing staggering amounts of data. To make it more complex, some systems may write data using the SMB protocol, while others rely on NFS.
In the life sciences world more than anywhere else, a coherent storage platform is essential to enable data-driven workflows.
Science teams need a platform that:
- Eliminates the need to copy voluminous data sets across systems
- Implements efficient data reduction mechanisms
- Allows multiprotocol access to the same data sets
- Provides parallel, fast, and unified access to data through file and object protocols, without performance penalties
- Enables programmability to script data processing sequences
- Seamlessly integrates with cloud-native applications
These requirements make it challenging to execute life sciences workflows on standard storage platforms, particularly when they are managed and provisioned as standard infrastructure components because they do not consider the seamless flow of those workloads.
Providing A Modern Data Experience for Genomics
Among Pure Storage solutions, FlashBlade ideally suits life sciences requirements. Designed to provide unified fast file and object storage (UFFO), FlashBlade seamlessly supports highly concurrent, high-performance environments with an ideal fit with HPC and AI/ML workloads such as Genomics, algorithm training, AI/NLP, and R&D.
FlashBlade natively supports demanding scientific workloads by providing consistent performance regardless of the data footprint (metadata, small or large files). It is built to be massively and linearly scalable both in capacity and performance, with support for up to 150 blades per system (across multiple chassis), and 256 files per filesystem.
The solution is architected to deliver PBs of throughput and low latency access to hundreds of millions of files, with exceptional performance for non-cacheable workloads.
FlashBlade provides a faster time to science and a modern data experience for Genomics thanks to the following characteristics:
- Faster data processing with end-to-end sequencing analytics up to 24x times faster, and workflow acceleration up to 3x faster thanks to built-in file compression
- Cloud support through Pure Storage AWS and Azure partnerships, with the ability to leverage cloud-native genomics applications
- Simple and predictable storage management thanks to Pure1 self-driving storage capabilities, drastically reducing time spent on infrastructure management and delivering valuable storage insights
- Cloud-like economics with Pure-as-a-Service, providing OpEx-based flexible consumption and reducing costs
- Seamless upgrades and expansions with Evergreen, providing peace of mind, ensuring infrastructure stability, and focus on scientific research
Organizations also benefit from Pure Storage’s broad ecosystem: for example, data can be sent to Pure Storage AIRI for tertiary analysis. Integrations with Portworx and cloud-native workloads are also supported. For file-based datasets, the capacity-optimized, QLC-based FlashArray //C platform can also make an excellent secondary storage target which is fully integrated with Pure1.
Conclusion
Genomics and Life Sciences is a highly competitive market segment where speed and seamless execution are primordial. With swathes of data to be analyzed, science teams need a dedicated platform that allows for frictionless, efficient, and fast data processing, without the hurdles of traditional IT, but also without the constraints of operating as an infrastructure island.
With FlashBlade, Pure Storage is ideally suited to serve the needs of the Life Sciences market. It does so by providing:
- a performant and scalable UFFO platform capable of seamlessly handling sustained parallel load, providing exceptional performance for both small and large files
- multiprotocol support and data reduction algorithms that reduce processing times
- ease of management and cloud-like economics for a no-brainer experience coupled with a simple and predictable pricing model
In addition, Pure Storage’s commitment to the Life Sciences market is confirmed by dedicated engineering teams with hands-on understanding and experience on the workflows, processes, and data sets specific to this vertical. The outcome: a strong footprint among the most innovative Pharma / Research / Genomic companies, which places Pure Storage as a privileged partner for existing and new research projects.