I started creating server build automation during a change freeze, immediately after New Year’s 2000, the Y2K bug apocalypse date that didn’t quite eventuate. Ever since that start, I have much preferred automated build processes to relying on people following a list of manual steps. One of the reasons for that is the principles of IT infrastructure automation fit nicely with the DevOps culture that enables faster application development.
I create build automation designed to have a human watching over, mainly watching for errors. Building automated error handling and verification is complicated and time-consuming. Watching that build process is acceptable when building a small lab. It was also great when three or four engineers built a couple of dozen servers for doctors’ surgeries.
The problem is that human operations are costly to scale, particularly to many locations spread over a wide geographic area. This is what is defined as the far-edge location. These locations might be retail stores, or delivery trucks, often places where business staff do their day-to-day work, interacting with the customers and directly generating revenue.
Increasingly, technology is either making the staff at these sites more productive, or adding ways to generate more revenue from the customers that visit these sites. But this technology has a cost, and business owners need to control those costs to turn that revenue into profit.
Control Far-Edge Costs
One of the important ways to control IT costs for the far edge is to ensure that one never needs to send a skilled IT engineer to sites. Everything that goes to the sites should be able to be installed and connected by the onsite staff, whether they are the driver of the truck or a checkout supervisor at the store.
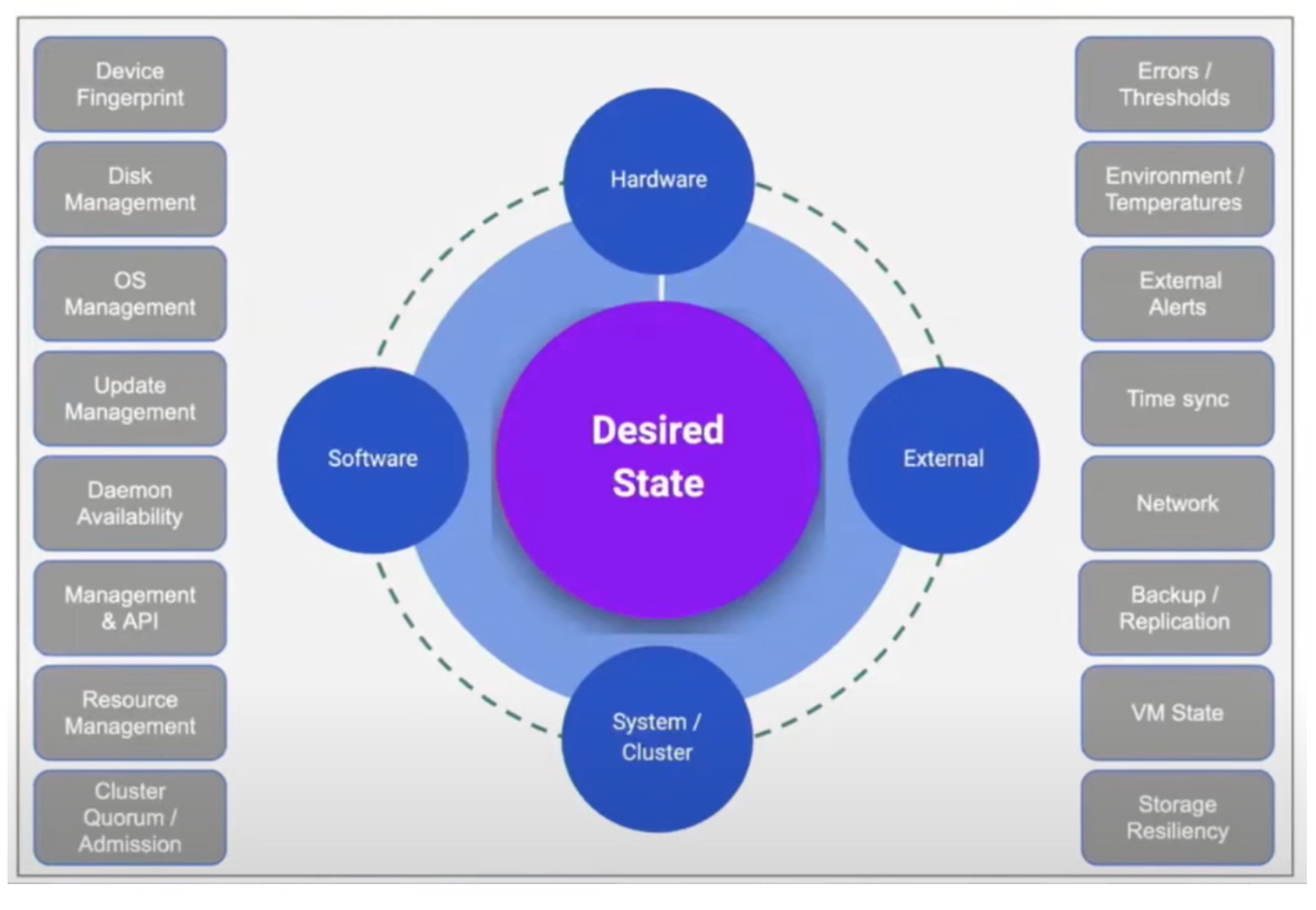
Once the hardware is physically installed, every other part of deployment and management must happen from a central console where the IT team can manage groups of sites and remotely resolve faults. Ideally, the platform used should automatically fix as many faults as possible, which brings us neatly to Scale Computing and its background in self-healing computing infrastructure.

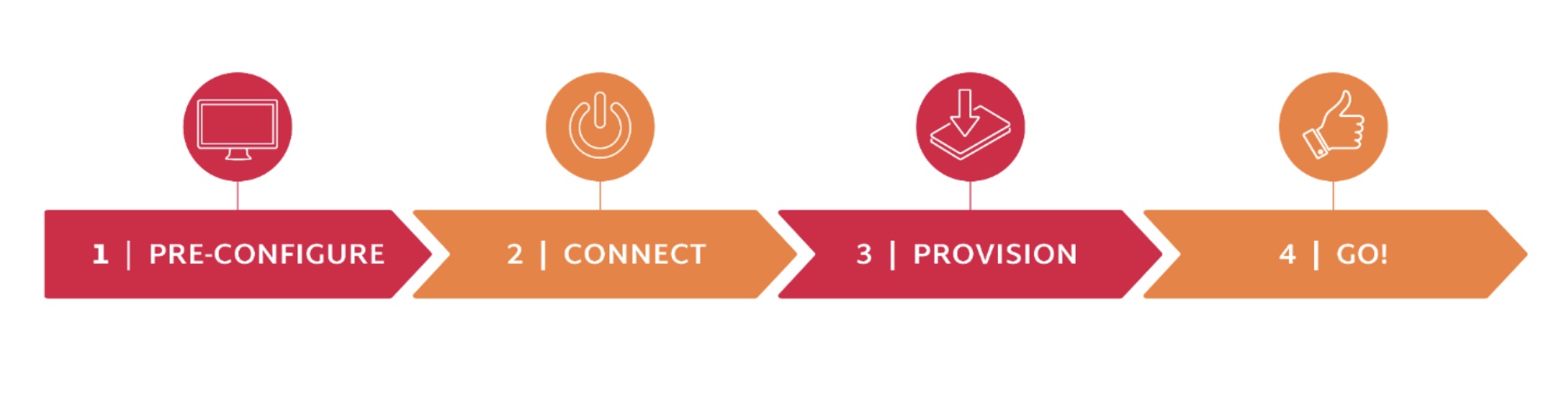
Zero-Touch Provisioning
Scale Computing has always designed SC//HyperCore HCI to look after itself as much as possible. SC//Platform extends to edge deployment and is the basis for Zero-Touch Provisioning (ZTP) of SC//HyperCore clusters at a grand scale.
ZTP was the centrepiece of Scale Computing’s recent presentation at the Edge Field Day event in San Francisco. In the live-streamed presentation, four clusters were deployed from a central console to five Intel NUCs. The “onsite” deployment was connecting power and ethernet to the appliances. Everything after that was achieved using the SC//Fleet Manager console, which had been pre-populated with the hardware IDs of the physical nodes.
In actual deployment, these hardware IDs are harvested from the fulfillment system that delivers the appliances to the site. SC//Fleet Manager is easily pre-populated with the IDs before the devices are delivered to the site. Once the appliance is powered up, it phones home to SC//Fleet Manager over the Internet and appears in the customer’s view of the console.
Application Platforms
SC//Fleet Manager handled a lot of configuration and initial setup for users, deploying the latest version of SC//HyperCore to the nodes, and deploying a set of standard initial VMs. The initial VMs might be the standard edge site servers with locally installed applications, or home to cloud-managed applications using platforms such as Google Anthos or Azure ARC-enabled applications.
SC//Fleet Manager can drive updates of SC//HyperCore to the clusters, and Scale Computing has an Ansible collection for managing multiple clusters over time. The Ansible collection is Red Hat certified and available on Galaxy for easy installation.
Scale Computing Removes Problems
Scale Computing’s approach of removing the burden of routine tasks and fault remediation from customers is widely liked. ZTP is an excellent part of continuing the story where Scale Computing can deliver large numbers of cost-effective clusters, or single nodes, to deployment at the far edge.
The Intel NUCs, using specific models that incorporate feedback from Scale Computing, make a great compute node to deploy in far-edge locations. Scale Computing also has its data centre-specific models for less constrained environments.
Scale Computing showed its commitment to partners by having Avassa and Mako Networks present at the Edge Field Day event in their offices.
Be sure to watch the Scale Computing presentations from the recent Edge Field Day event, and keep up with what the other delegates think at TechFieldDay.com.