It was merely a few years ago that AI/ML first hit the tech scene for mainstream use. In the beginning, select companies dabbled in it, and those that did had to devise and roll their own implementation using whatever resources were available to them. But as AI/ML enjoyed broader adoption, the market around it started to grow.
Gartner predicts that in 2023, AI/ML will be among the top workloads to drive infrastructure decisions. At the heart of this is rising storage needs which remains a major stumbling block preventing AI/ML from becoming prevalent.
At the recent Storage Field Day event, IBM gave a presentation that outlined the storage challenges that are slowing adoption of AI. Dough McGuire, Global Director of Sales in Storage for AI, Big Data, introduced Storage Scale, IBM’s fastest growing segment in the data and AI storage portfolio, and explained with customer success stories, how it makes handling of massive unstructured data cost-effective and simple, and sets companies up for AI success.
Barriers to AI Adoption
The state of data in 2023 is vastly different than it was before. In the past ten years, the amount of data created, captured, copied and consumed globally has tripled and quadrupled. This has both a good, and a bad side. On one hand, the compound annual growth rate (CAGR) at which data is growing has presented an opportunity for enterprises to tap into the wealth of information that is locked in it. But, hot on the heel of that has arrived the predicament of storing and processing all of that data.
80 to 90% of the data created and collected is unstructured, and companies employ point solutions to handle it. This has only deepened the divide in the infrastructure, creating innumerable islands of data and technologies. Access and management of these silos with the overflowing amount of data that is coming in, is the biggest struggle for 95% of the companies.
As AI/ML entered the scene, enterprises were given an elegant way to churn value out of their data. But the effort of deploying AI/ML workloads on enterprise infrastructures is met with the shortcomings of traditional storage systems that are not cut to handle their sky-high performance and scaling needs.
A Global Data Fabric
An organization’s ability to draw maximum value out of its data and conquer the ascent of AI/ML rests on squarely meeting the data challenges. To avoid falling behind in the AI race, companies must use an architecture that first and foremost acts as a superhighway for large-scale workloads, but concurrently offers great support for general-purpose workloads which most enterprises have. This is everything that Storage Scale brings to offer.
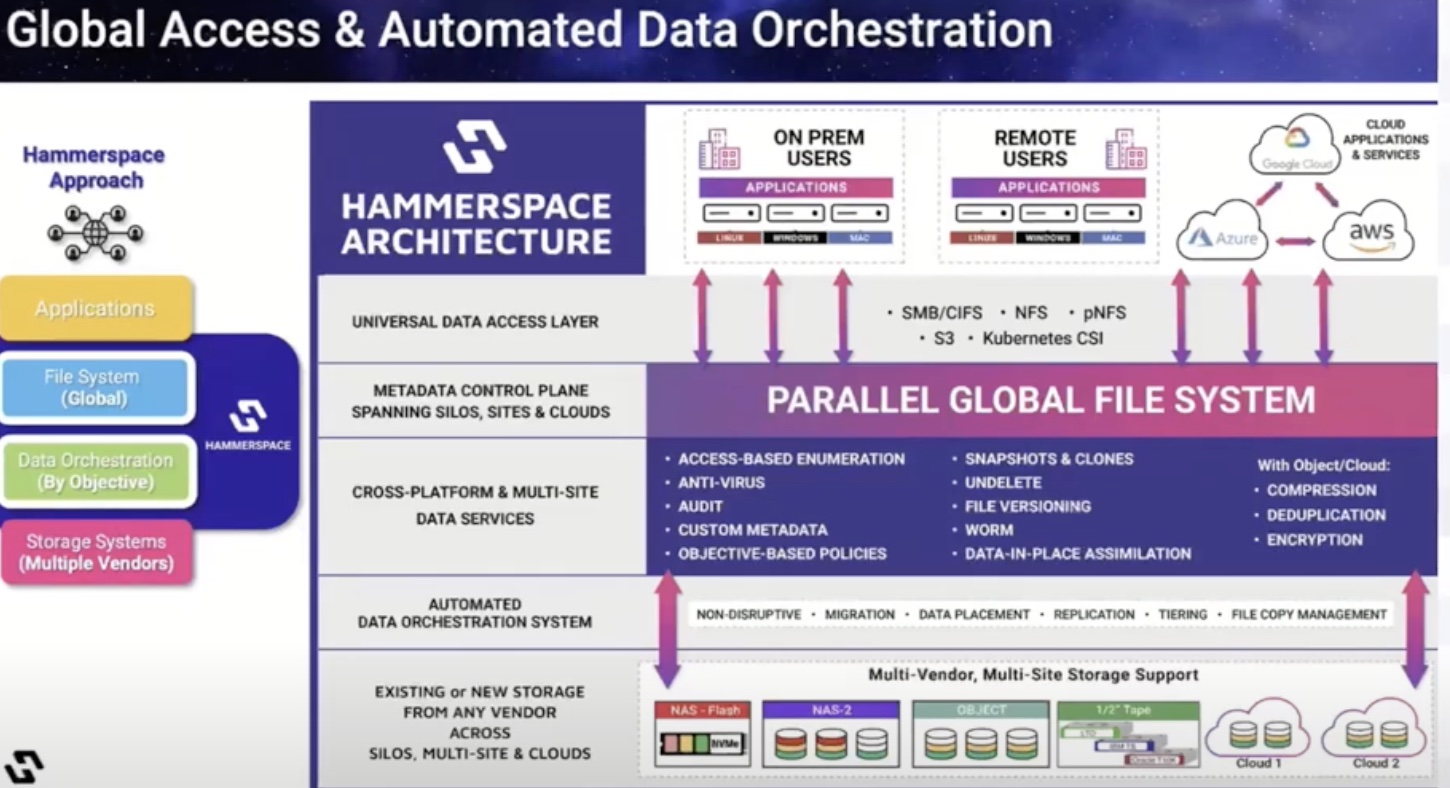
IBM’s Storage Scale System is a software-defined object and file data storage system that is built to readily support the performance and scaling needs of AI/ML workloads. But Storage Scale is more than just a high-performance enterprise storage. It deploys a global data fabric for AI that fosters geo-distributed collaboration through elimination of data silos and management pains, and most importantly, enables easy access of data with a common data plane that spans the enterprise.
Serving High-Profile Use Cases with IBM Global Data Platform
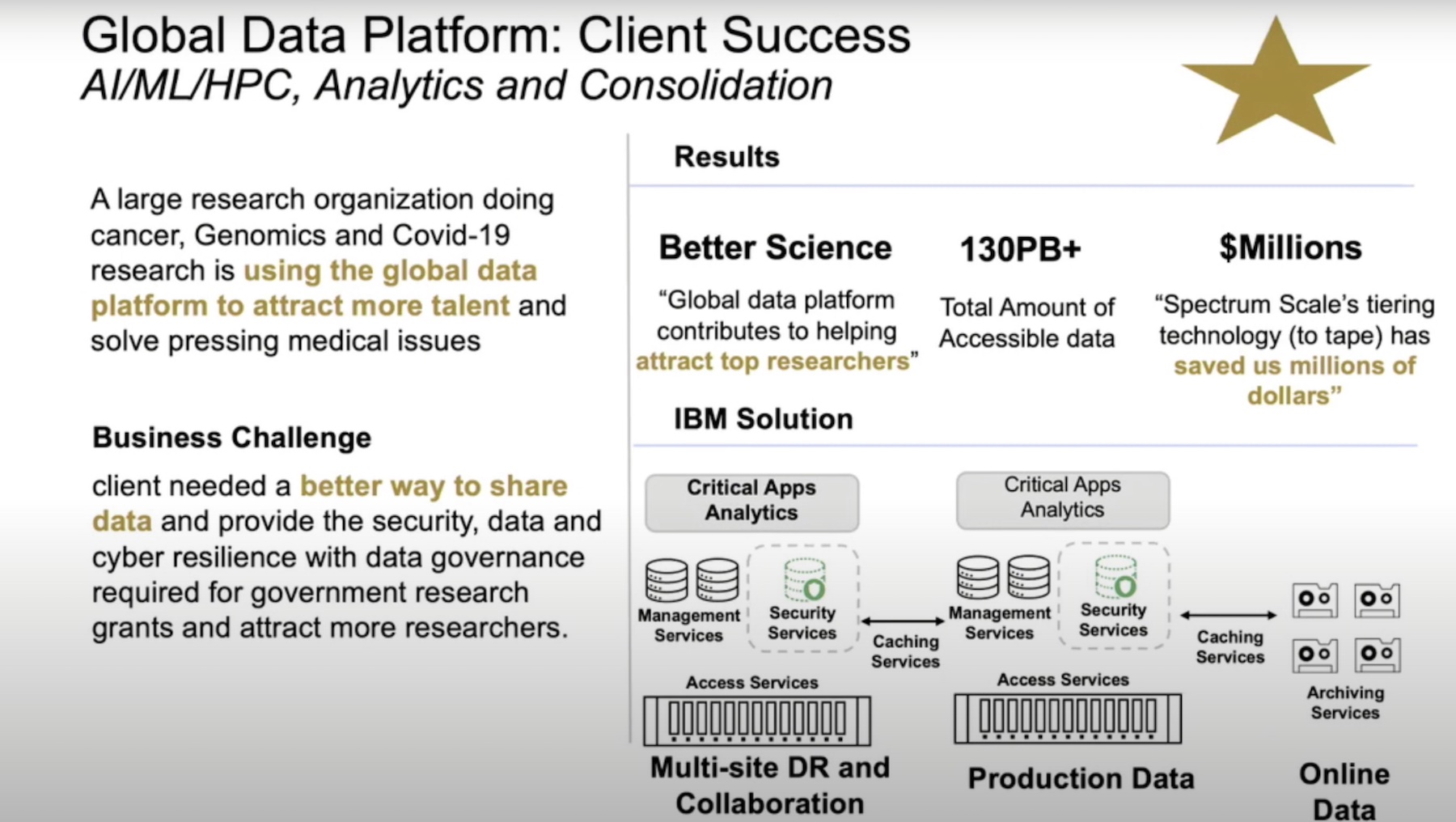
Mr. McGuire referred to an array of client success stories while explaining the key benefits of the Storage Scale offering. He informed that IBM’s Global Data Platform attracts large numbers of research companies and banking organizations that have a high bar for regulatory compliance and cyber resiliency.
The Global Data Platform serves those clients by enabling them to set up two production sites that can share data between themselves. With caching services running in between, the platform maintains a single source of truth for data, decimating silos and saving companies top dollars by not having to move petabytes of data to public cloud where storage is typically cost-prohibitive.
Through transparent sharing of data and workloads across public and private clouds and the edge, the Global Data Platform significantly shrinks cloud storage footprints. Caching services between sites ensure that there are no stale data copies.
For businesses wrestling with data in scattered addresses, the Global Data Platform offers a way for applications to reach and use them no matter where the storage is located, or what interface is being used. The platform allows speedy and consistent access of a single copy of data from any storage system, reducing the need to make and keep multiple copies in different locations.
The Global Data Plane provides a high availability environment where organizations can create high-performance tiers for AI/ML use cases and run concurrent workloads.
At the heart of the platform is cyber resilience that organizations, especially regulatory industries ask. With a breadth of security and ransomware capabilities based on the NIST framework built into it, the platform identifies, protects, detects, responds and recovers, giving data active protection from all kinds of threats.
Wrapping Up
IBM’s Global Data Platform offers two key things – performance and access – that are paramount to adopting AI/ML and harnessing the value of data. It provides an agile, secure and available environment where data can move freely without the constraints of silos. The common data plane ensures swift and uninterrupted access to the same data from various interfaces and locations. Its high performance is vital to optimizing workloads, and making possible a wider adoption and maturity of AI.
For more information on IBM’s Storage Scale offering, check out IBM’s deep-dive presentations and demos on the solution from the recent Storage Field Day event.