It’s conventional wisdom that GPU is the preferred hardware for AI. AI’s voracious appetite for compute demands a technology capable of performing complex logical operations with speed, power and parallelism. But with GPUs becoming scarce, is it reasonable to take extraordinary measures to obtain them, or can some CPUs support the demands of complex neural networks?
For the past year or so, Earl Ruby, R&D Engineer at Broadcom, and his team, have been experimenting with various hardware to find the answer. They tested scores of AI/ML accelerators to measure their levels of efficiency and compatibility with vSphere, VMware’s trademark suite of server virtualization products.
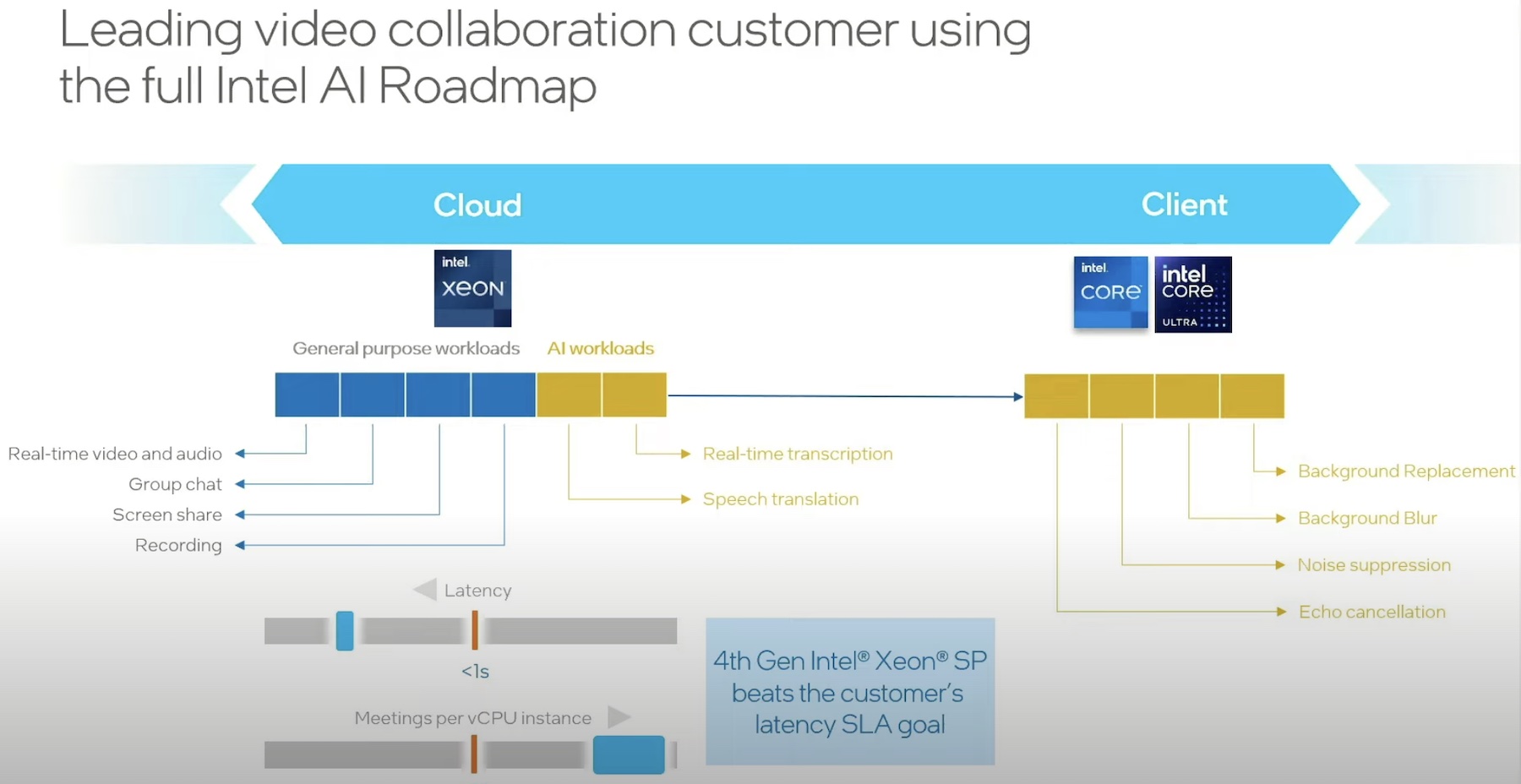
In particular, Intel’s Xeon line of processors ignited their interest. The CPUs are fast and efficient at running calculations, and they seem to be getting better at analyzing data with each generation. With AI/ML workloads, these CPUs tested surprisingly well for inferencing and training of LLMs, sending shockwaves through the community.
VMware Private AI with Intel
In November of 2023, at VMware Explore Barcelona, VMware by Broadcom announced Private AI with Intel, an initiative to make AI models private, performant and prevalent. VMware’s Private AI reference architecture constitutes Intel GPUs for hard-core AI workloads, but for lower-tier AI models, it vouches for Intel AMX, a technology that powers the Xeon CPUs.
vSphere already offers a gamut of features around security and management. Capabilities like virtual TPM, vSphere Trust Authority, VM encryption, coupled with NSX’s built-in micro-segmentation and advanced threat protection capabilities, and integrations with popular identity and access management (IAM) solutions, make vSphere a holistically secure solution.
The next step is to build a fully private AI stack in on-premise datacenters that works with vSphere, and makes it available everywhere. “Areas such as privacy, data protection, security, and resiliency are core to the Private AI vision, and the associated products that we will be launching,” says Ruby, at the recent AI Field Day event in California.
An Integrated Hardware Block
What makes GPUs the holy grail of AI? “GPUs are just specialized matrix processors. They can perform mathematical operations in parallel on matrices of numbers,” comments Ruby.
In 2020, Intel introduced AMX for Sapphire Rapids, a technology that performs matrix math. AMX or Advanced Matrix Extensions is an AI engine on board the Intel Xeon scalable processors. This newly added instruction set is built into the chip to deliver acceleration for inferencing and training operations. AMX accelerators reside inside each core providing max efficiency from within, without requiring discrete hardware.
Two key components power Intel AMX – tiles and Tile Matrix Multiplication (TMUL). Tiles are made up of eight 2D registers, each a kilobyte in size. When data comes in, these registers hold large amounts of it making it accessible to the TMUL. TMUL is the accelerator engine that works on the data. Placed together with the tiles, it performs matrix-multiply computation for AI workloads, computing bigger chunks in single cycles.

“It’s a form of parallel processing, be able to process multiple data sets with the single instruction. The goal of this software is to make sure that both the host and the AMX unit are running simultaneously to maximize the throughput and performance,” he explains.
Although the 4th Gen Xeon Processors’ microarchitecture was the first to support the technology, it was only the beginning. AMX has been a mainstay in Xeon CPUs since.
Running LLMs on CPUs
Supplementing GPUs with CPUs in certain cases unlocks immense business value. “I always tell people, use CPUs when you can, use GPUs when you must. So, if CPU performance is good enough for your use case such as inferencing, then use it. If you are batch processing ML workloads, if it’s an LLM with less than 15 to 20 billion parameters, you can do it on CPUs,” says Ruby.
Xeon CPUs compute data at a speed that is adequate for inferencing workloads in certain use cases. Ruby demonstrates the performances of Ice Lake, the 3rd Gen of Xeon, and Sapphire Rapids to visualize this.
In the demo, the former struggled to load a Hugging Face 7 billion parameter model loading it at an agonizingly slow speed that is not fit for production. By contrast, Sapphire Rapids loaded the same model under seconds.
A VMware Environment with Intel Hardware
The vSphere + Intel environment constitutes Sapphire Rapids or Emerald Rapids CPUs, guest VMs running Linux kernel 5.16 at least, or the recommended 5.19, and vCenter and vSphere 8.0U2.
On the software side, Intel offers a breadth of optimized and most updated AI toolset on its website. “AI/ML software packages and frameworks have been adding support for AMX, and will continue to improve and extend that support,” informs Ruby.
What makes the Intel AMX and vSphere combination a hit? First, it offers the twin power of both the technologies making it possible to deploy both AI and general workloads side by side. “The idea here is that as customers replace older hosts with Sapphire Rapids or Emerald Rapids, they not only get the performance improvements for traditional computing, but they also get AMX capabilities for AI/ML,” explains Ruby.
The second value it offers is the flexibility. “Xeon and vSphere on-prem and cloud environments are pretty ubiquitous, and you’ve this optimized AI software stack that can quickly scale in hybrid environments. Customers can run their entire end-to-end AI pipeline with CPUs, using built-in AI accelerators.
Wrapping Up
CPUs certainly make a sustainable choice of hardware for less demanding AI use cases, when the goal is cost and energy optimization. Specifically using Intel Xeon Scalable processors for AI/ML workloads not only allows enterprises to rest their desperate hunt for GPUs, but supplement pricey specialized hardware with something that is infinitely more economical and adequately performant.
Be sure to check out Intel’s presentation where Intel shines light on VMware’s perspective and vision on this. Also check out VMware’s two-parter presentation from the AI Field Day event to learn how you can build and deploy private AI models on VMware infrastructure using Intel’s hardware.