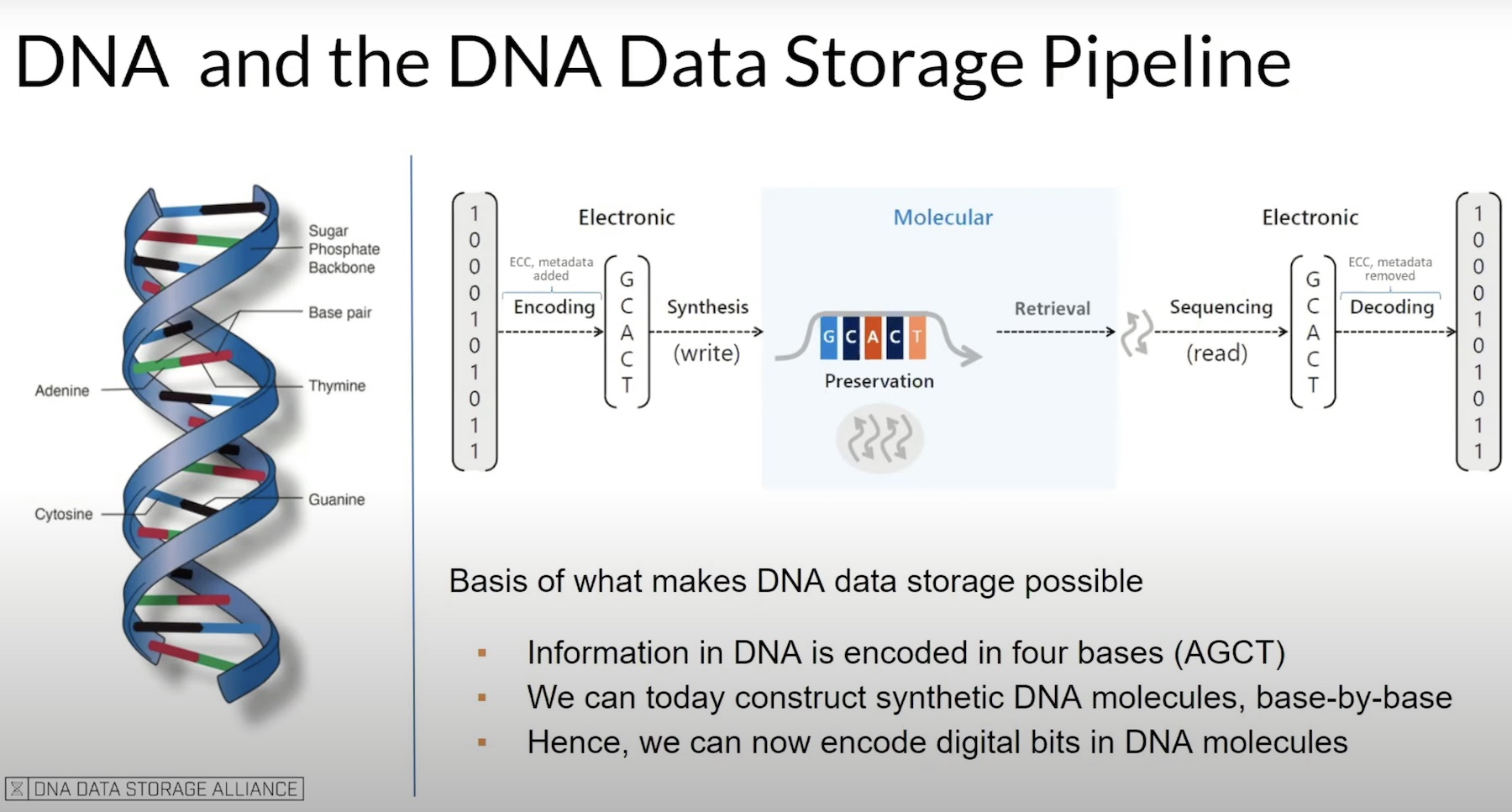
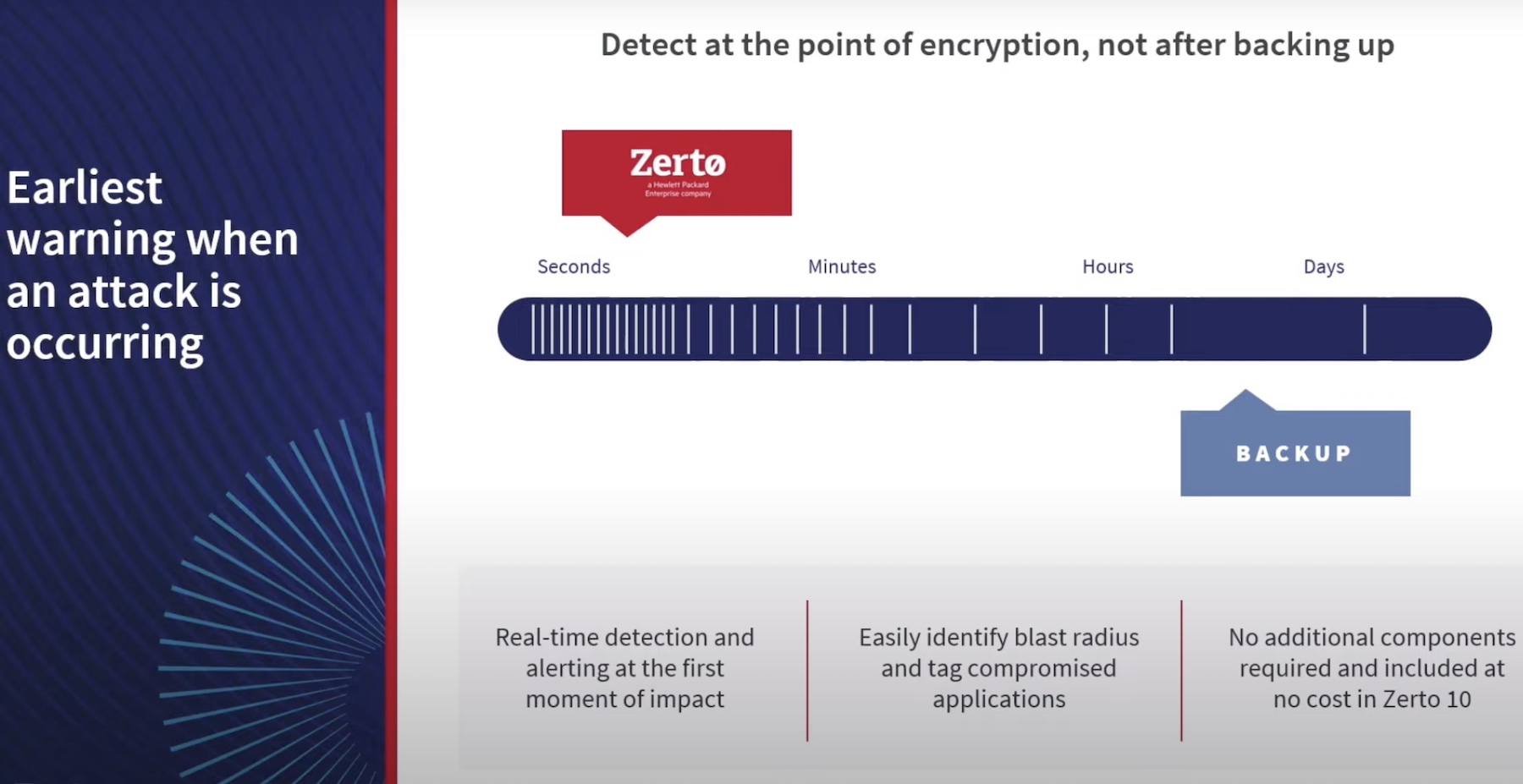
As computer systems, computer networks, and the data within, continue to grow, engineers fear that the blast radius of even a single component failure can have intense ramifications. Often, the bigger components powering the datacenters are the biggest risks, but the smaller component failures too can potentially be the cudgel, now that everything is twice its size.
In this Delegate Roundtable – Managing the Blast Radius as System Components Get Bigger – recorded in Santa Clara, California at the recent Storage Field Day event, Stephen Foskett and the attending panel of delegates sat down to dissect this premise, and brainstorm ways to limit the scope of impact.
Wide-Spread Consequences
While on one hand, computer processes have shrunken in size, and form factors have lost dimensions, on the other hand, CPUs have gained more cores and we have some of the largest networks in the history. And data inflation – that has been the most staggering of all. The growing size and scale of things thickens the impacts of outages and failures, causing a growing anxiety around the blast radius of such events. Case in point, the epic Amazon outages.
These outages have had multiple causes, but they all had wide-spread impact. In the light of the succession of recent events, it is clear that major outages are hugely disruptive, not just for the immediate businesses that sustain them, but customer businesses and individuals. What is a matter of a few websites going down for a few couple hours translates to thousands of users being cut off from big parts of the internet, not to mention the dire effects on industries like the stock market, banking or healthcare.
And the nightmare doesn’t stop there. A few hours off of the internet would have been a small price to pay, but the impact of an outage frequently tends to cascade from one service to other – affecting innumerable far-removed services – causing widespread problems. This results in more than momentary chaos or unhappy customers – it costs big businesses billions of dollars in losses.
Through a Different Lens
Enrico Signoretti opines that the problem is a bit different than how it is perceived. As data grows exponentially in volume, in support of that, storage system capacity has gone up to avoid bottlenecks. But that is unrelated to the blast radius. Engineers have always had to worry about the blast radius, even when things weren’t at this scale. According to him, the bigger concern is how fast can something be rebuilt if it’s broken. Given the growing service level expectations, the least time it takes to get things back up, the fewer zeros get added to the net loss.
Glenn Dekhayser posited a differing point of view. According to him, the real problem is “the upfront architecture of the system”. Back when it was only a small amount of data, backing up was easier. But in 2022, companies are dealing with petabytes of data, and backing up that amount of data requires them to have multiple copies in disparate environments. That raises two concerns –economics, and sustainability.

A Common Concern
While the panel was divided on their positions on the blast radius, they all concurred where the real challenge is. It’s not about a component failure or the size of it. It’s how fast things can be restored after you lose an array in a region.
Circling back to the topic at hand Moderator, Stephen Foskett raised the question that was at the heart of the discussion- is the blast radius of a bigger system actually bigger than that of a smaller system?
While the answer is evident – the blast radius is in fact bigger now – the reason he cites for that is “enterprises haven’t kept up with the growth of capacity. Essentially our systems are objectively bigger today and that’s driven by external factors and economics that have more to do with the vendors and the producers of those components and the limits of the system architecture, than they have with the use of data.”
Frederic Van Haren ties it to the workloads and what they demand. Today’s workloads, be it data analytics or a less demanding kind, ask a lot more out of the infrastructure than those before, he said.
Dekhayser explains that with data sprawl in full swing, companies have petabytes of data stored in arrays. When one such array goes down, the blast radius of that event gets significantly larger if that exact same data is not stored in another array in another region, and if that data can’t be moved fast enough over a network to bring up a new array. At the current state, that could take months.
Richard Kenyan says “Storage is no longer the bottleneck – it’s the rest of the infrastructure.” He reminded the panel that today high speed networks are inexplicably expensive. Small businesses can’t afford it, and even the bottom Fortune 500 companies don’t have access to it.
Wrapping Up
It is clear that the blast radius today is a lot bigger than it used to be, even if in an adjusted way. That’s all the reason why containment of that radius needs a lot more attention and work. When nearly anything from undetectable defects to silent errors can shut the whole system off and send ripple effects across the board, it communicates the message that we need to find more ways to limit that impact. Even though all conditions are not ideal, we now know that there are a lot of factors staring us in the face that can each contribute to accomplish that end.
Watch the full roundtable above and other similar discussions from the recent Storage Field Day event to get a refreshing perspective on current day storage.