Artificial intelligence and deep learning workloads can take a massive toll on server resources as each part of the process require different parts of the stack to operate properly. Instead of building a stack for each individual part of the process, IT practitioners use tools like the Matrix software platform from Liqid, which they showcased at May’s AI Field Day event, to compose a single server to dynamically utilize the resources it needs for AI workflows — all while managing it from a single pane of glass.
The Push for Composable Infrastructure
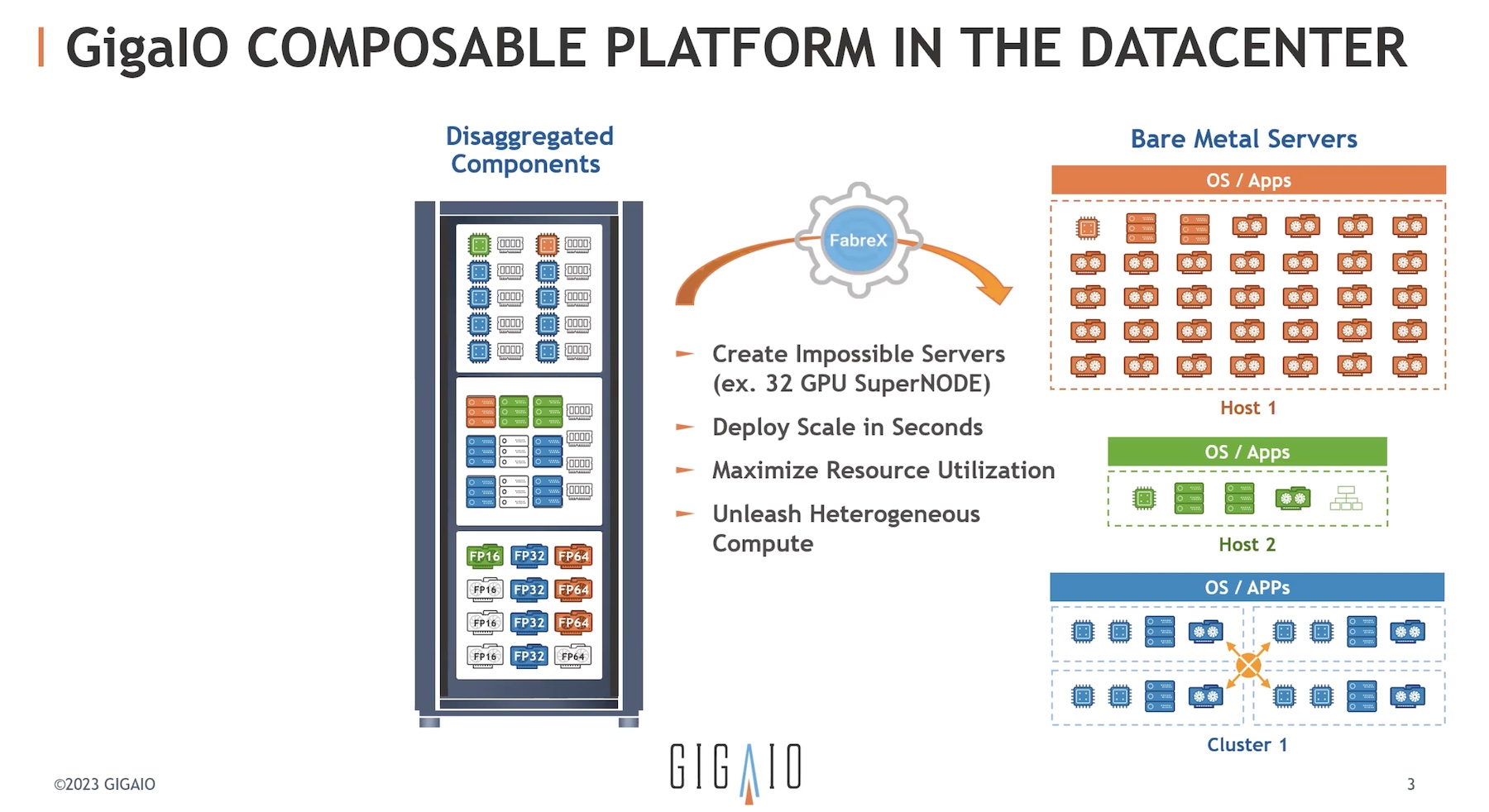
As we draw closer and closer to the limits of Moore’s Law, hardware manufacturers are finding new ways of reducing the form factor of chips and server blades while also maintaining, if not increasing their performance. One method of doing so actually subverts hardware altogether, leveraging software to make the most of server resources: composable infrastructure. In a composable model, a layer of software sits above the hardware in a server stack, providing a single pane of glass to manage all of the goings-on within the server.
The software abstraction layer that drives composable infrastructure allows IT practitioners to allocate their resources more effectively and make the most of their existing hardware instead of letting each part of the stack operate in silos. This factor makes a composable approach ideal for resource-intensive operations, like building and running AI models.
Combining AI with Composability
Liqid sits at that crossroads of AI and composability. The Liqid Matrix software acts as the command center for servers running AI processes, allowing IT staff to choose the parts of the stack they want to be involved in each stage of their AI workflows. That way, instead of building a stack for each individual part of the process, a single server can dynamically alternate between the hardware it needs, while keeping the data that’s crucial to every AI model at the center of the process.
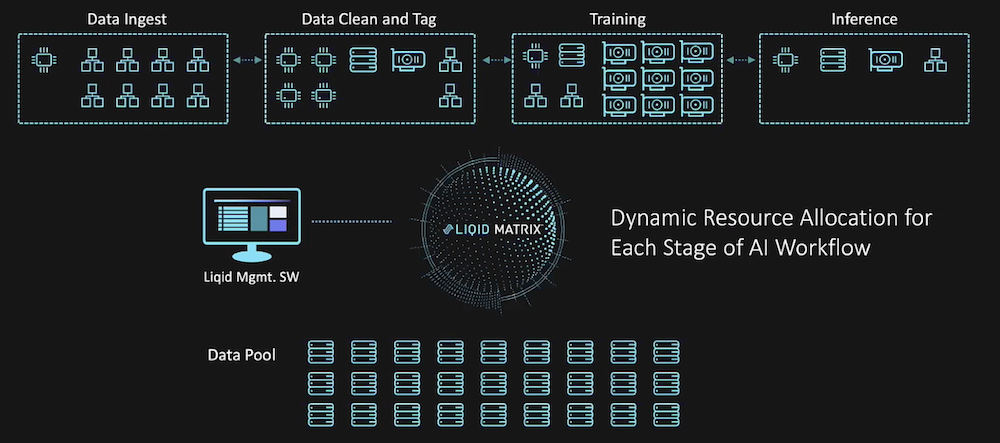
In practice, Liqid’s composable approach to AI infrastructure saves organizations both time and money. By keeping the data pool at the center of AI operations, there’s an overall reduction in latency since no data needs to be transferred between compute nodes; it’s simply switched via fabric between nodes to meet the needs of that specific workflow. As such, a server stack can be built to near-minimum specifications while still achieving the necessary output for AI workflows.

Digging Deeper into Disaggregation with Liqid
Liqid’s CEO and co-founder, Sumit Puri, presented the capabilities of their Matrix platform at May’s AI Field Day event. According to Puri, Liqid’s Matrix is akin to the virtualized hypervisor but for on-premises servers. It slices and dices individual servers to meet the needs of the workflow at hand so that only the necessary amount of resources, or rather, the right combination of resources, are being used at any one time.
During the discussion, Puri noted that, because of that disaggregated, hypervisor-like nature, Matrix can dynamically reassign memory like Intel Optane to serve practically any need of an AI workflow, including DRAM. From the perspective of the host compute node, that disaggregation makes everything seem like a local connection, making data transfer quick and easy compared to going back and forth between servers.
Zach’s Reaction
Liqid’s Matrix software platform gives IT practitioners the tools they need to dynamically compose a single server to do the work of several in regards to AI workflows. That way, instead of running siloed operations that eat up time and money, organizations can operate fast-paced AI models while managing it all from the top down.
Learn more about what Liqid Matrix provides to AI operations by watching all of their AI Field Day presentation, visiting their website, or listening to this episode of the Utilizing AI podcast featuring Liqid’s Sumit Puri and Chief AI Architect, Josiah Clark.