The Reality is It Can’t Be Defined But You Can Cheat Now
 Last week I had the pleasure to attend a roundtable with four IT influencers led by Keith Townsend: the Gestalt IT Showcase. It was an interesting experience and we had an entertaining discussion around the concept of Data Gravity and the idea of Data Infrastructure Framework.
Last week I had the pleasure to attend a roundtable with four IT influencers led by Keith Townsend: the Gestalt IT Showcase. It was an interesting experience and we had an entertaining discussion around the concept of Data Gravity and the idea of Data Infrastructure Framework.
The first part of the discussion, around data gravity, sparked a couple of interesting comments that I want to report here but before doing that, let me quickly explain why data gravity is a problem, especially now in the era of the cloud.
Why Do We Build Data Mass?
Data needs to be collected and stored somewhere to be used over time. If you want to analyze data, sooner or later, you have to consolidate it in a single repository and make it accessible by applications. Leaving data in a distributed fashion, maybe at the edge where it is collected, would make many operations inefficient and others even impossible to perform. This is why we build data lakes and other forms of data aggregation – it is simply the most efficient way to store and operate on data.
Data Gravity, Its inertia, and the Speed of Light
When you start consolidating data, the only thing you can do is to keep doing it. There is no reason to start multiple data lakes in the end. It just adds complexity, therefore costs. Everything is perfect then, until you need to access data.
It’s highly unlikely you will ever need all your data all the time. To access the data you need, there is some initial inertia due to the searching and preparation activity that needs to be done. In some cases, an ETL (extract-transform-load ) process will be needed to make it usable for the specific job at hand.
The other major issue is the speed of light (and poor network connectivity, of course). The farther you are from your data, the longer it takes to access it. Data and applications need to stay next to each other to solve this problem but, unfortunately, this is becoming harder and harder to achieve. In fact, a few years ago we had everything clear and simple, concentrated in one place with data, compute, and applications in the same data center. Now, with the cloud, things are getting muddier.
One-size-fits-all does not apply. We moved from on-prem to cloud-only IT strategies first, to understand later on that hybrid is a better, more balanced, approach. And with hybrid, I also mean multi-cloud. For several reasons, we now have applications that can run on-prem or in one or more of the many public clouds available. This trend makes data access more complex because you may need data stored far from where your applications reside and that’s when the limitations imposed by gravity, inertia, and speed of light kick in!
How to Defy (or Cheat) Data Gravity
You simply can’t defy data gravity. If you have 10PB of data and you want to move it closer to the application, it can be done but it’s very expensive and time-consuming. But, as hinted to at the very beginning of this article, there are more solutions than in the past to overcome limitations imposed by physics.
The most common solution is to work the other way around by moving applications closer to data. From this point of view, Containers and Kubernetes have made things easier than in the past. Deploying your application to a different Kubernetes cluster is very simple and now hosted Kubernetes services are available from all major service providers. The only limitation of this approach lies in the application itself. In practice, you can rely on any external service that may not be available on another cloud or on-premises. Therefore, your application is more complex and expensive to develop and maintain, and the concept of federated Kubernetes to keep everything aligned and compatible at the infrastructure level starts to make much more sense.
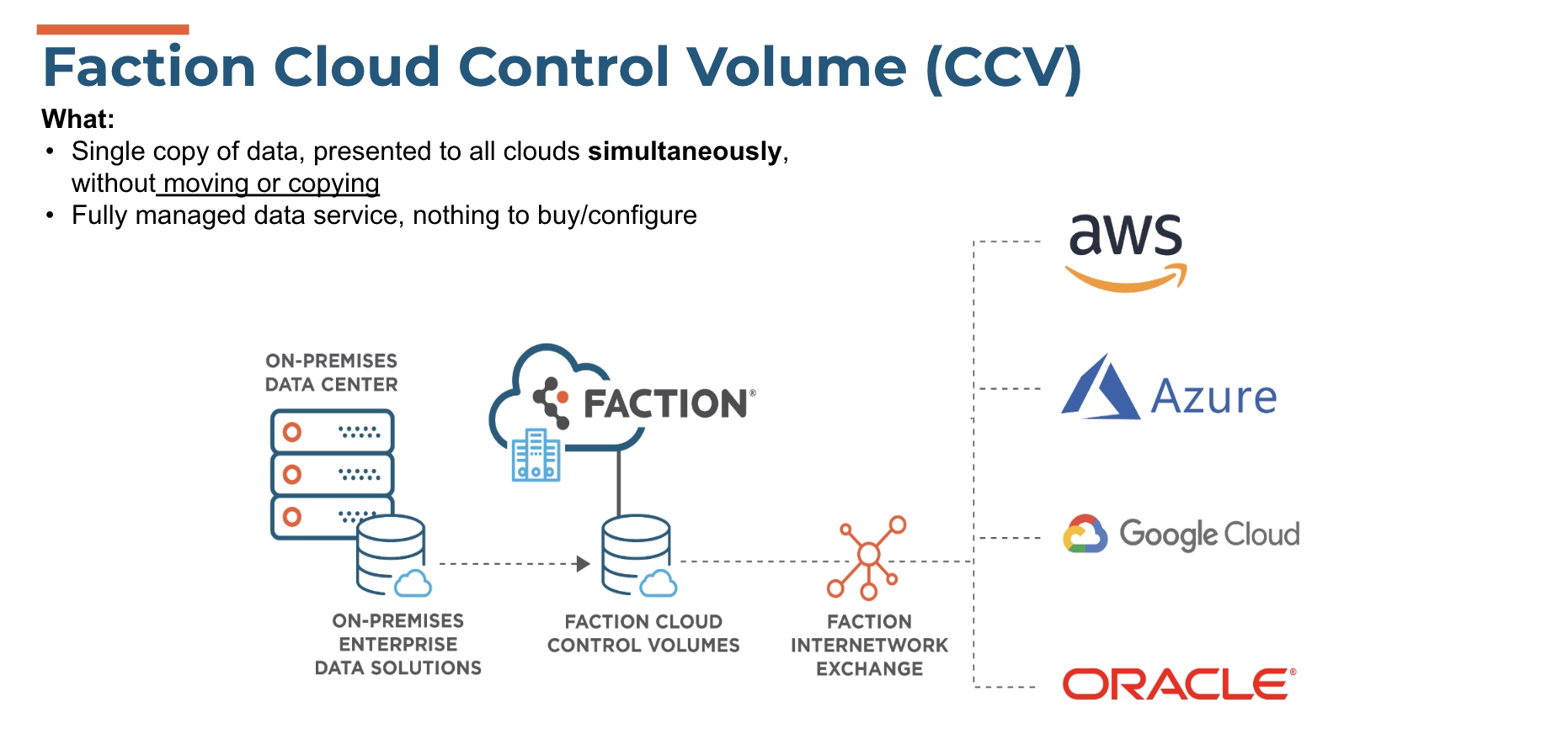
When moving the application is not feasible there are other mechanisms that can be helpful, including better connectivity, data replication, and several forms of pre-fetching and caching. Better connectivity is expensive but relatively easy. In fact, most end users can now have direct and very fast connections to their service providers, allowing to get access to data faster even if it’s not as close as local. The problem with this approach lies in the egress fees, but alternatively, you can use smart caching mechanisms to minimize data access (there are several solutions) and optimize any single data transfer including pre-fetching data to minimize latency. However, these mechanisms are not always optimal and data replication across clouds is something that is now available from many solutions. Keeping specific data sets in sync can be less expensive than other mechanisms because of the low $/GB offered by some cloud providers. The technology is out there now; it is only about finding the right balance between access speed and cost.
Closing the Circle
Data gravity does exist and you can’t avoid it, and data consolidation is necessary to have a complete and consistent view of your data. Fortunately, you don’t need all the data at once and there are many solutions to mitigate data gravity.
In this article, we mentioned some of the potential solutions and how new technology can help to get the best from the multi-cloud while limiting the impact of data gravity. We have only scratched the surface here, and there is much more to tell, solutions to discuss, and best practices to analyze. Stay tuned for more.
In the meantime, take a look at the recordings of the GestaltIT Showcase (here and here), and feel free to chime in on Twitter by adding us (@Esignoretti, @CTOAdvisor, @ArjanTim, @DataChick, @SFoskett) and the hashtag #GestaltITShowcase to your tweets. I’m sure you’ll come up with some interesting ideas as well.