Data Science with python
I joined the Intel Innovation session called “Python Data Science and Machine Learning at Scale”. As one of the delegates, I was able to interact with the presenters and ask questions.
Most people know Intel as the company providing high-tech components for computer systems such as microprocessors, network interface, flash memory, chipsets, to name a few. However, over the years, Intel has invested significantly in software to maximize the efficiency of computer systems. Intel is well-positioned to play a leader and innovator role as they have intimate knowledge and understanding of the underlying hardware.
About six (6) years ago, Intel started the Python project to support Python machine learning initiatives and Intel’s Artificial Intelligence (AI) offerings. The goal is to connect many existing Python tools used by the data scientists to Intel performance libraries such as the Intel® oneAPI Math Kernel Library (oneMKL), and the Intel® oneAPI Data Analytics Library (oneDAL). The Intel tools are drop-in replacement tools only needing a minimum of code changes. According to Intel, the drop-ins can accelerate in some cases up to 400x.
The principles of the project are to deliver the highest performance possible at scale and do so with maximum usability for developers. By hiding and abstracting the underlying complexity, developers can focus all their energy on solving project-related challenges instead. Additionally, Intel continues their commitment to supporting the open-source community and open standards. Considering that many AI projects get started in the open-source community, it is good to see Intel contribute, give back to the community and support open standards.
An AI pipeline consists of multiple stages, and each stage has different requirements and needs. However, Intel stated that they would keep investing in accelerating all stages of an AI pipeline, from data loading through learning, including training and inference.
Why Python?
Python is the ideal programming language for data science for a few reasons. First, there are many libraries and frameworks to choose from that facilitate coding and reduce development time. For example, the NumPy library is for scientific computation, SciPy for advanced computation, and scikit-learn for data mining and analysis. Secondly, the driving force behind Python is a very active community and is continuously evolving. Third, it is a syntax-friendly language and easy to learn. And finally, the availability of a powerful package management and deployment tool from Anaconda, called Conda. Conda takes care of the Python package installation and its dependencies, and includes virtual environment management. All the packages are centralized in a repository and regularly updated.
Intel’s AI Python offering
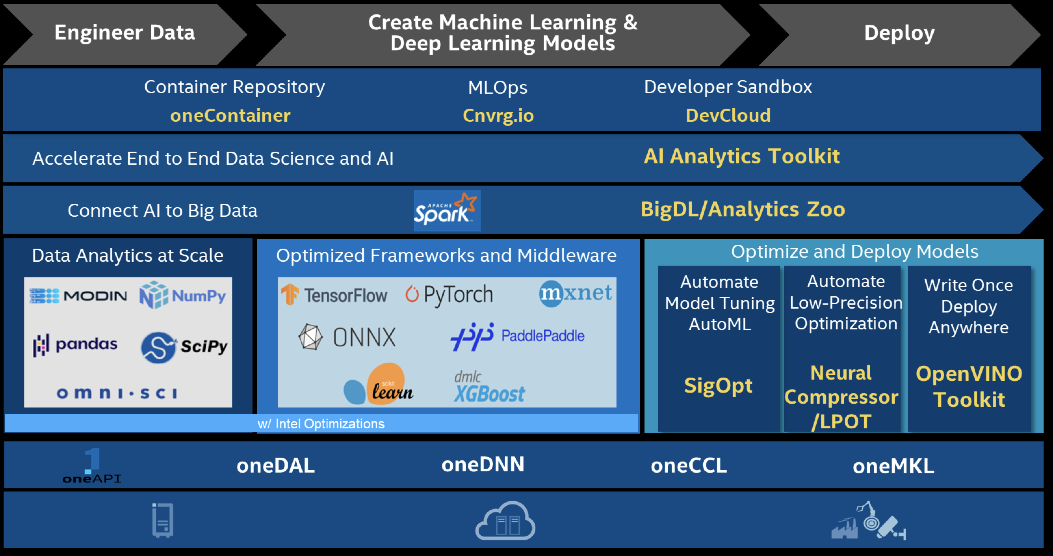
The diagram below shows the comprehensive portfolio of AI tools that make up the Intel AI ecosystem. In addition, the tools and frameworks required to deliver an end-to-end solution from data preparation, training to production are covered.
Optimizations are powered by oneAPI libraries, such as oneDAL, oneDNN, oneCCL, and oneMKL as seen at the bottom of the diagram. Thus, a developer can start with a base framework or tool and replace it with an optimized version with minimal code changes. The optimized packages are available on Anaconda and deployed like any other package. The best location to find the packages is on the Intel channel on the Anaconda cloud.
The AI team at Intel has created a video demonstration of the Python data science portfolio at scale.
oneAPI
The oneAPI open standard is at the core of the Intel optimization effort. A unified API to provide an abstraction layer between developers and various accelerator architectures, GPUs (Graphics Processing Unit), FPGAs (Field-Programmable Gate Arrays), and AI accelerators. Often, developers are dealing with AI pipelines consisting of multiple hardware architectures. The oneAPI standard provides a cross-platform developer stack optimized for performance and scale.
XPU
Intel defines the mix of architectures as the “XPU” vision. Support is not limited to Intel-only architectures and includes support for GPUS in the datacenter. NVIDIA CUDA. For example, it means developers can also run their Python code using popular libraries on multiple GPUs taking advantage of the extended compute and memory on both the host and the device. Coupling the benefits of a programming language such as Python with the abstraction of the underlying architectures gives developers more flexibility. An additional benefit is that you can develop based on one architecture and swap it out for another later on (late binding). The Intel Data Parallel-Python (DPPy) package provides a simple, unified offload programming model using Python API standards. Since it is all based on open-source, anybody can extend the model and add other architectures.

Summary
Intel has produced an impressive portfolio of Python packages to accelerate and scale compute-intensive packages such as NumPy, SciPy, Pandas, and scikit-learn. The packages are built around open standards and are a powerful addition to the Python ecosystem. The portfolio has everything needed to achieve end-to-end performance for AI workloads. Additionally, development across multiple hardware targets is supported with the flexibility to tune each target separately. Many modern AI workloads require multiple hardware targets in the same pipeline.
How to get started?
The best way to get started is with the Intel oneAPI AI Analytics Toolkit (AI Kit). The AI Kit is well documented and comes with complete installation instructions. In addition, the landing page has links to related packages and tools such as compilers. There is also a dedicated discussion forum called the “Intel Distribution for Python Forum” to exchange ideas and ask questions to the community.
You can learn more about the Intel Python offering by watching their presentation. You can also view the following resources from Intel:



