Previously I discussed the need for a more complex approach to data orchestration.
The modern world of data has a scale that boggles the mind.
The scale of data is often framed in terms of various Vs: Volume, Velocity, Variety, and sometimes the additional V of Veracity. Modern systems create scale challenges on each of these dimensions that we’ve not really had to deal with before.

Human Generated Data
The issue of volume is well known and much discussed. The handheld cameras embedded in every smartphone have led to an explosion in photographic and video content (and, sadly, the demise of blurry flying saucer pictures) known as human generated data – and it all needs to be stored and managed somehow. Similarly, the advent of cheap internet connected sensor devices, or Internet of Things, has increased the amount of machine generated data that, you guessed it, also needs to be stored and managed.
It is unremarkable to predict that more data will be generated tomorrow than today. What is remarkable is how little attention has been given to the management and maintenance of systems that handle this data. The most popular approach has so far been to simply accumulate as much data as possible in as many piles as possible (while also trying to build a single Grand Unified Pile or Data warehouse) and then wait for the magic of AI to arrive to solve the problem for us.
But there are better approaches.
Automation for Human Assistance
The scope and scale of modern computer systems have reached the point that they are, in many cases, beyond the comprehension of unaided human intelligence. We rely on various tools to help us to manage them, and it would be remarkable if the systems for dealing with data were any different.
Until now we have been content to muddle along with fairly simple tools, much as a craft industry can manage with only simple un-powered hand tools. But as we take a more industrialized approach to our industry, craft tools need to give way to more sophisticated tools, just as hammers and chisels gave way to power tools, the moving assembly line, and programmable multi-axis robotic arms.
Adding more complex and powerful tools allows we as humans to apply greater leverage; a single human can accomplish much more with a good set of tools than that same human can with just their bare hands. Data management is no different.
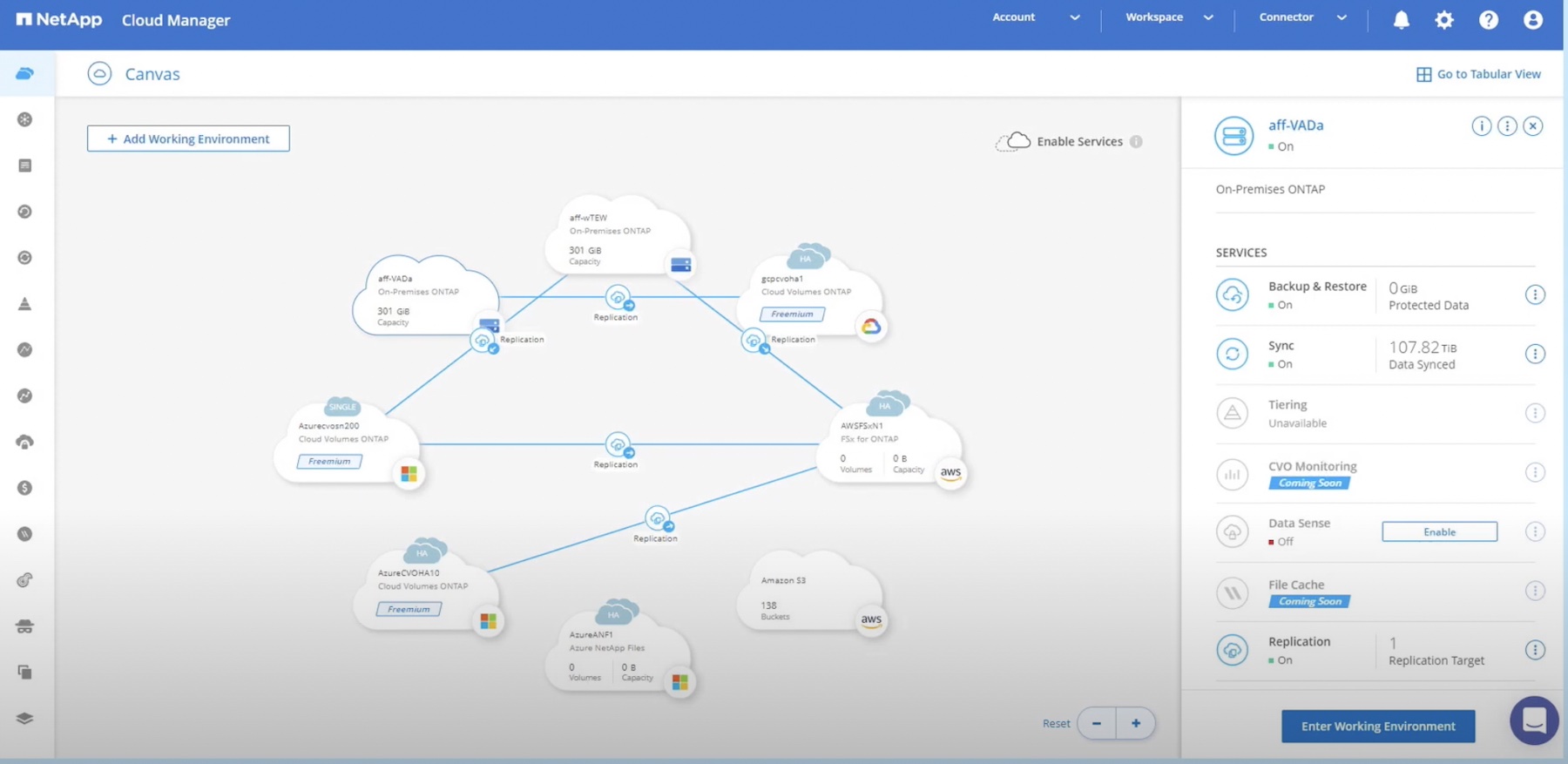
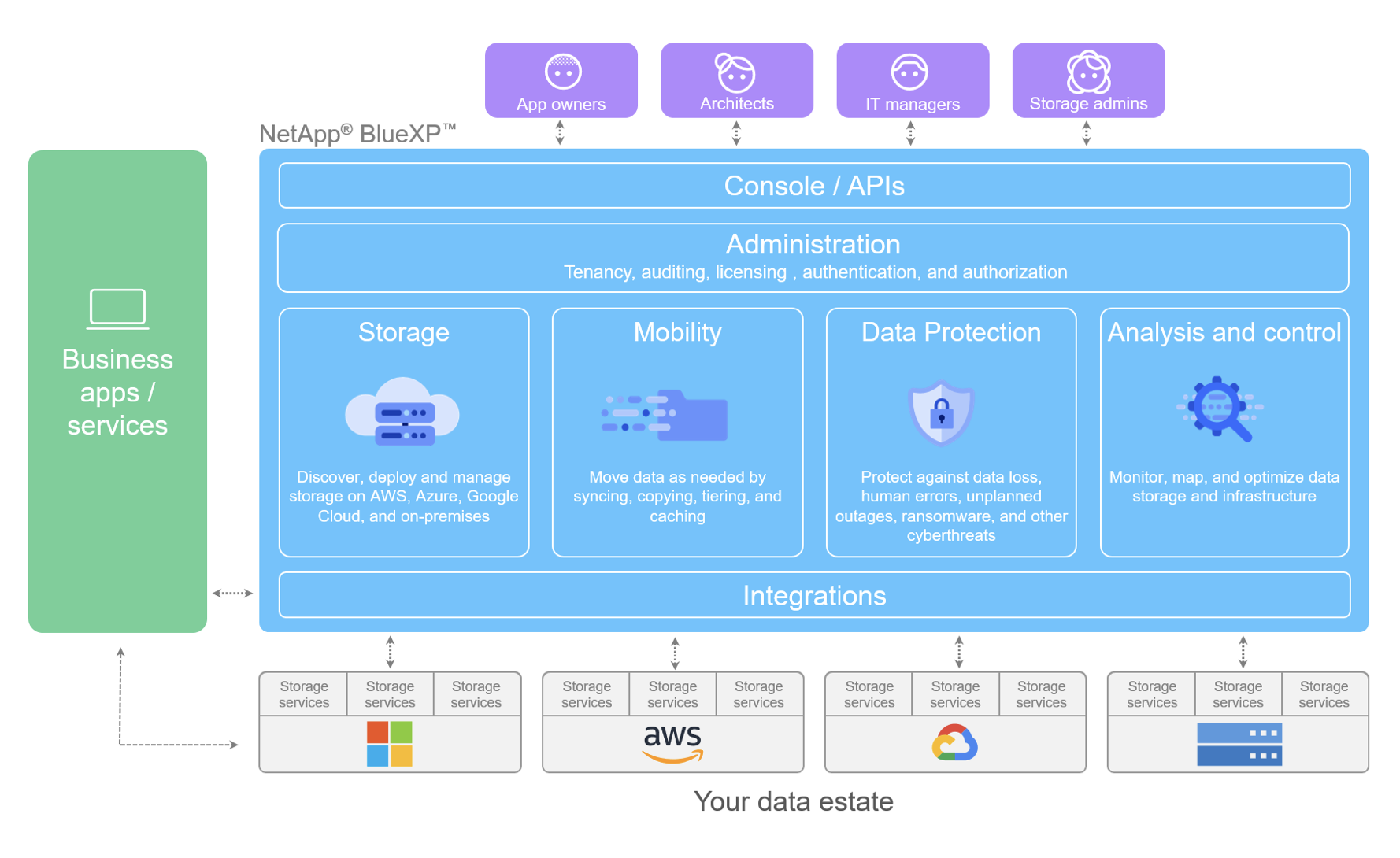
This is the idea behind NetApp’s Data Orchestrator. It helps to automate repeated data management tasks so that they can be handled in the same consistent fashion every time, across a large fleet. This kind of management-at-scale is too time consuming to perform manually, and humans are fairly terrible at repetitive consistency. We get bored and we make mistakes.
By moving the data control plane into a centralized tool, we can scale our processes and policies across our entire data fleet. This provides the human operators with far greater leverage than unaided teams, which translates into not only faster and safer operations, but a more enjoyable job with fewer tedious and repetitive tasks.
Make Good Easy
If the most secure, reliable, and maintainable option is also the easiest one to use, that’s the one that people will choose. If we continue to insist on forcing people to use complex, cumbersome, and manual methods for managing data at scale, those people will continue to bypass these methods in order to get their work done, thereby decreasing security, reliability, and maintainability in the process.
Instead we should design systems that make the authorized user’s goal easy to achieve, and only make the wrong things difficult. If I’m an authorized user just doing my job, my tools should make it easy for me. Finding the data I need and putting it where I need it to be should be simple. Even better if the system knows my regular needs and anticipates them, such as by automating common tasks.
Having access controls apply automatically to new datasets based on established policy means the controls will always be in place. Manual steps are too easy to skip when people are in a hurry, and we’re constantly being told how much faster the world is, and how we have to do everything quicker.
If the dataset I need contains sensitive data, it should be automatically masked. If data must stay within a geographic location, it should be easier to work with in that location than anywhere else. Temptations to bypass good practice should be replaced with rewards for doing the right thing.
NetApp Fabric Orchestrator can help to enforce a data deletion policy across all applications without relying on human operators to remember to remove data. Fabric Orchestrator can customize the behavior of a Data Fabric to automate data proximity based on application or usage patterns.
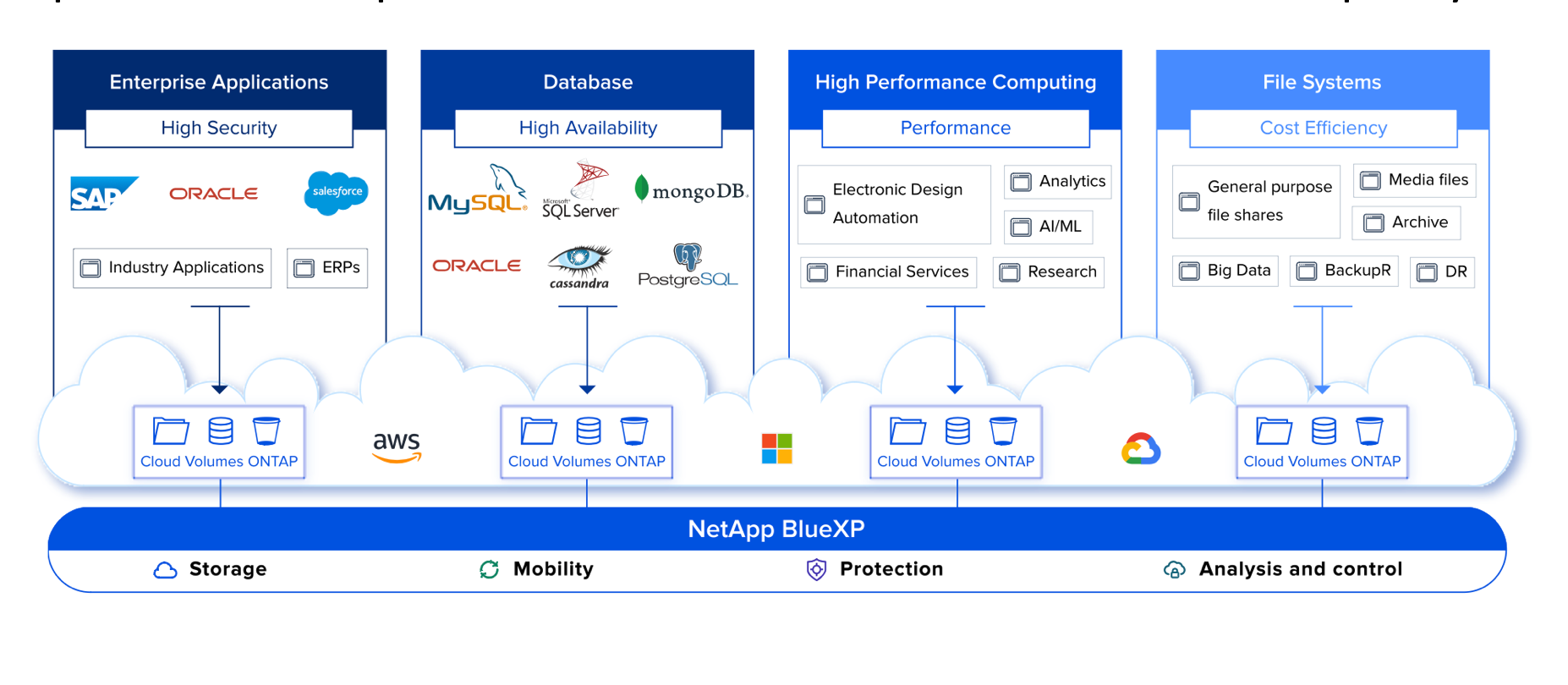
NetApp is fairly keen to play well with others and has deep partnerships with all the major public clouds. NetApp is also quite happy with data that lives on-site, or in private clouds, or that spans across a selection of all of these options.
While public cloud has been around for some time, and on-site systems have been in use for decades, the world of hybrid-/multi-cloud is still quite new. With edge-computing on the rise and an explosion of the Internet-of-Things, there isn’t one right structure for your data fabric. You’ll need a data partner that can cope with change and help you to manage whatever choices are best for you, both today, and in the years to come. NetApp’s vision for data orchestration is worth a look.