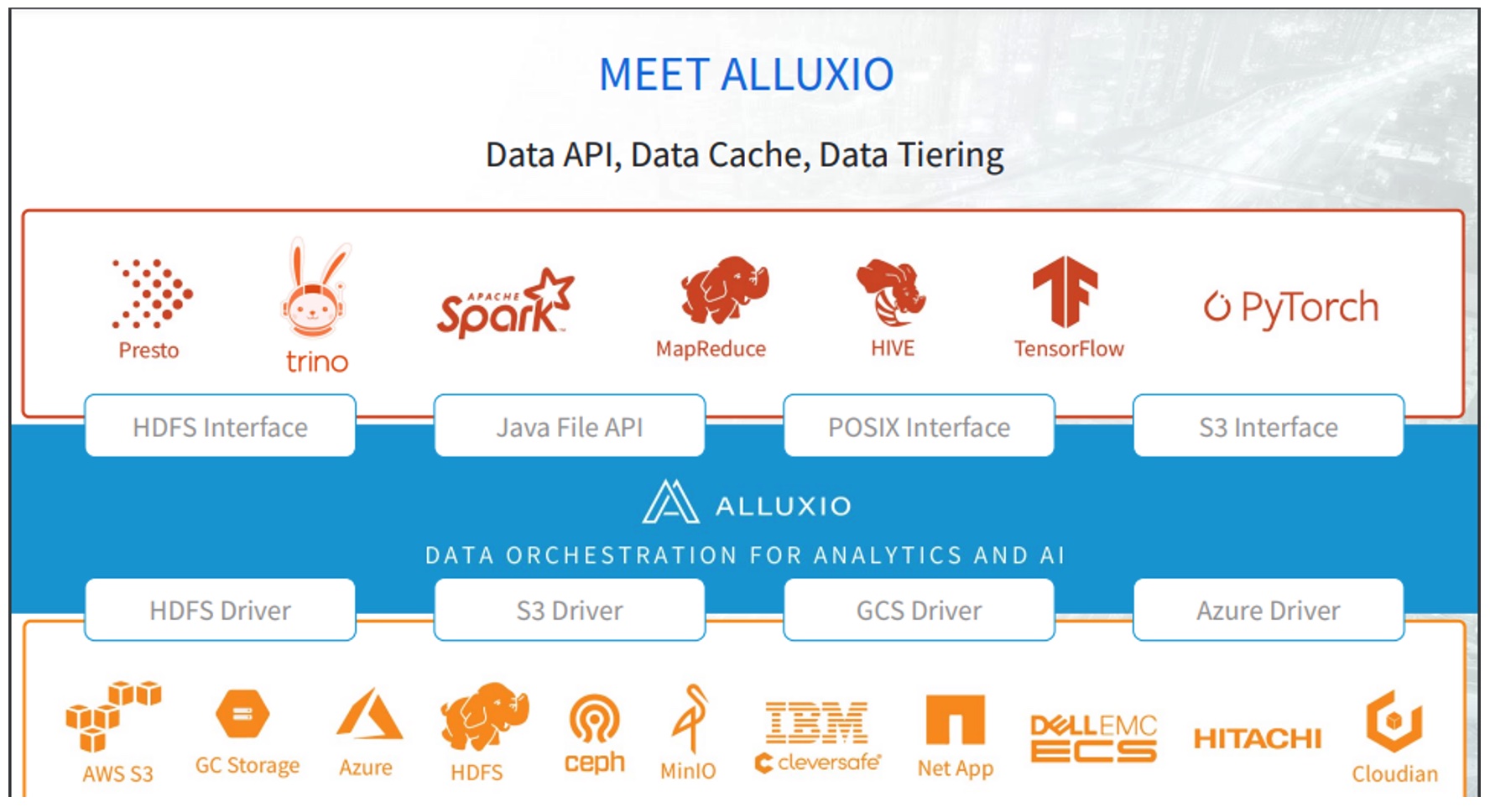
Machine learning is unlike any other enterprise application, demanding massive datasets from distributed sources. In this episode, Bin Fan of Alluxio discusses the unique challenges of distributed heterogeneous data to support ML workloads with Frederic Van Haren and Stephen Foskett. The systems supporting AI training are unique, with GPUs and other AI accelerators distributed across multiple machines, each accessing the same massive set of small files. Conventional storage solutions are not equipped to serve parallel access to such a large number of small files, and they often become a bottleneck to performance in machine learning training. Another issue is moving data across silos, storage systems and protocols, which is impossible with most solutions.
Three Questions
- Frederic: What areas are blocking us today to further improve and accelerate AI?
- Stephen: How big can ML models get? Will today’s hundred-billion parameter model look small tomorrow or have we reached the limit?
- Sara E. Berger: With all of the AI that we have in our day-to-day, where should be the limitations? Where should we have it, where shouldn’t we have it, where should be the boundaries?
Guest
Bin Fan, Founding Member of Alluxio Inc . Connect with Bin on LinkedIn and on Twitter @BinFan.
Hosts
- Frederic Van Haren, Founder at HighFens Inc., Consultancy & Services. Connect with Frederic on Highfens.com or on Twitter at @FredericVHaren.
- Stephen Foskett, Publisher of Gestalt IT and Organizer of Tech Field Day . Find Stephen’s writing at GestaltIT.com and on Twitter at @SFoskett.
For your weekly dose of Utilizing AI, subscribe to our podcast on your favorite podcast app through Anchor FM and check out more Utilizing AI podcast episodes on the dedicated website, https://utilizing-ai.com/.