
The Barren Land of Storage Fragmentation
Why are storage consolidation projects failing so often, and what keeps fueling the fragmentation and complexity? Today, it is commonplace to find several storage systems and storage vendors coexisting in a single organization, each fulfilling a particular purpose.
The inherent operational complexity of managing multiple products and vendors is aggravated by a lack of versatility, scalability challenges, and pricing mayhem. Storage exists as multiple independent islands that all support specific protocols, propose different storage services, and have different performance profiles.
Pooling the aggregate storage capacity and making it available across systems is yet another issue. While storage virtualization may deliver on this promise, but it also comes at a price and adds another layer of complexity behind the scenes.
Legacy Code, Acquisitions, and Portfolio Sprawl
Some of the most widespread storage products sold today share significant portions of code with their predecessors. In some cases, code can be up to one or two decades old. The old way of designing storage products still lingers around, with incremental code updates and attempts to bake in novel technologies, leading to trade-offs and sub-optimal outcomes.
Some vendors are also affected by innovation challenges. When R&D isn’t working well enough, or when a rising underdog is seen as a threat, large vendors trigger the acquisition card. Effective product integration remains rare or might take several product releases to happen. The result is bloated product portfolios where several internally competing products offer similar features.
Customers are the ones who pay the price of inefficiency by having to make architectural choices out of thin air, without knowing if they made the right bet. Customers are used to utilizing specific storage products for particular use cases. They do not always see the issue of operating inefficiently, because this is the way storage has worked for the past decades.
Tenets of Storage Fragmentation
Putting aside organizational matters (organizations working in silos, geographical boundaries, multiple decision centers, storage systems mandated by application vendors, etc.), there are technical reasons for storage fragmentation.
Analyzing the previous section provides cues to several root causes:
- Different performance tiers associated with various types of storage media used, each with different performance, capacity and cost attributes
- Legacy practice of mapping products/performance tiers to specific use cases, based on use case criticality, performance/latency/capacity requirements, and cost vs. business outcome analysis
- Incomplete features or protocols supported by products due to segmentation per use case/performance tier
Perhaps the most striking point is that storage media dictates use cases and, subsequently, features. If media would be affordable, capacity abundant, and performance outstanding, such media could be relevant for all use cases, from the simplest to the most demanding.
The Goldilocks Zone of Storage Media
If there was a single media type (or a “Goldilocks zone” of storage media), then perhaps a single storage array could cover a comprehensive range of use cases, provided that it implements the most popular storage protocols and data services.
The good news is that in 2020, this Goldilocks zone exists:
- 3D XPoint flash memory (also known as Intel Optane) operates at extremely low latencies, has incredibly fast read/write speeds, and astounding media endurance. Its downsides are a high price and limited media capacity
- QLC 3D NAND flash memory ideally complements Optane: QLC is capacity-oriented, has a very low $/GB price, and has read speeds similar to Optane. Its downsides, however, are a limited media endurance and slower write speeds
A storage architecture able to integrate both media types and to mitigate their downsides is the answer to the challenges highlighted previously.
StorONE AFAn – A True Next-Gen Storage Array
StorONE has taken a blank slate approach to storage when architecting their AFAn platform (AFAn stands for All-Flash Array.next), also branded as S1:AFAn.

Figure 1 – A rendered view of StorONE’s AFA.next
The AFAn is StorONE’s answer to the challenges developed in the previous sections. AFAn uses best-in-class storage media, combining performance and capacity tiers into an optimized single pool of storage. This storage platform is in a unique position to support a broad variety of use cases without incurring any penalty, be it cost, capacity, or performance.
The following sections will cover general information; an in-depth review of the architecture and data services will be available in follow-up, deep-dive blog posts.
Performance and Tiering
S1:AFAn uses Optane flash as a storage tier, which is in stark comparison with most vendors, who generally use Optane as a small caching tier in front of TLC 3D NAND. StorONE claims that the use of Optane as a read cache by their competition makes them lose the advantage of its staggering write performance.
A core function of S1:AFAn is S1:Tier. This function automatically moves data across multiple tiers of storage. S1:AFAn data writes are immediately committed to Optane. After a certain threshold has been hit, data is then moved in a large sequential write to QLC media. The sequential write is important as it ensures QLC flash media wears out slowly and evenly. Beyond QLC, customers can add even lower performance tiers such as hard drives or cloud-based storage options for long term archival purposes.
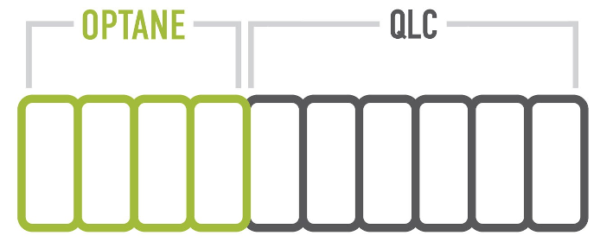
Figure 2 – Data is first written to Optane, then moved to QLC in large stripes to prevent media wear and free up the Optane tier.
When it comes to data reads, data present on QLC can be read at similar throughputs to data stored on Optane, there virtually no read penalty for having data stored on a much cheaper data tier.
Each system is delivered with four Optane drives; StorONE claims that just four Optane drives are sufficient to deliver 1 Million IOPS random reads, while reaching for 300K IOPS sustained writes
Protocols and Data Services
S1:AFAn supports file protocols (NFS, SMB), block (iSCI, FC) and object (S3). The combination of high performance and high capacity makes it a suitable platform to cover multiple data tiers without suffering any penalty.
StorONE built a data services framework delivers what is called a “Five Star Safety Rating”, where each star represents a particular data service. If we exclude S1:DirectWrite, which is StorONE’s implementation of direct write to Optane without the use of a cache, the following four services are available:
- S1:HA, a feature which remediates the lack of high availability capabilities in NVMe drives
- S1:vRAID, StorONE’s RAID implementation with rapid automated rebuilds and no need for hot spares
- S1:Replicate, allowing replication from a primary site to a DR site, with the ability to replicate data to different performance tiers at the DR site
- S1:SNAP, providing unlimited snapshot capabilities as well as nested snapshots without performance impact.

Figure 3 – StorONE AFAn Data Services
Conclusion: Use Cases and Benefits
Unsurprisingly, the use cases for a consolidated, high-performance next-generation All-Flash Array are very broad:
- Real-Time Processing
- AI / Machine Learning / Deep Learning
- Hypervisors
- Databases (MS SQL, Oracle)
There is no particular entry point or usual path for adoption. Customers can start using StorONE AFAn for any of the listed use cases and gradually onboard additional workloads once they feel comfortable to do so and end up with a consolidation storage infrastructure.
From a benefits perspective, AFAn helps organizations achieve the following outcomes:
- Achieve true storage consolidation
- Significantly reduce operational complexity
- Benefit from best-in-class storage performance
- Support a broad range of workloads and protocols out of the box
- Start small and scale as needed
- Contact-free installation, support, and operation (a welcome feature in normal times, and even more welcome in the midst of a pandemic)
These outcomes place StorONE on a promising path to truly achieve the dream of one generation of storage engineers; find the holy grail, the one storage array to rule over all workloads. Stay tuned for the next blog posts which will cover in-depth the product architecture, as well as performance and data services.



[…] More and more vendors are coming to market with Optane-based storage solutions. It still seems that only a small number of them are taking full advantage of Optane as a write medium, instead focusing on its benefit as a read tier. As I mentioned before, Crump and the team at StorONE have positioned some pretty decent numbers coming out of the AFAn. I think the best thing is that it’s now available as a configuration item on the StorONE TRUprice site as well, so you can see for yourself how much the solution costs. If you’re after a whole lot of performance in a small box, this might be just the thing. You can read more about the solution and check out the lab report here. My friend Max wrote a great article on the solution that you can read here. […]
[…] StorONE Breaks Storage Silos with Optane, QLC-Enabled AFA.next Posted in News […]